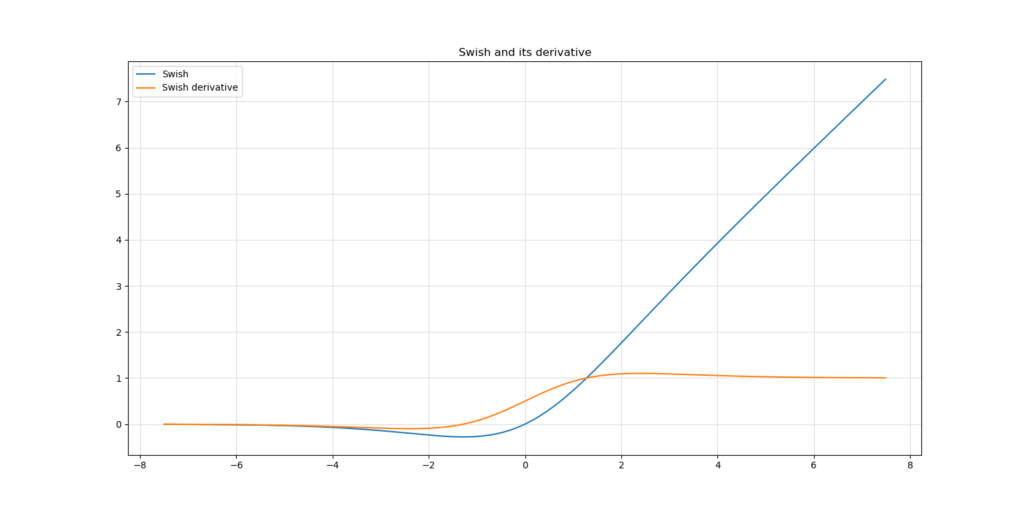
While Swish reportedly improves model performance (Ramachandran et al., 2017), it still does not allow you to avoid Vanishingexploding gradients
Even though the vanishing gradients problem is much less severe in case of Swish, only inputs of x>=2 result in gradients of 1 and (sometimes) higher. In any other case, the gradient will still cause the chain to get smaller with increasing Layers.
First, it is bounded below. Swish therefore benefits from Sparsity similar to Relu. Very negative weights are simply zeroed out.
Second, it is unbounded above. This means that for very large values, the outputs do not saturate to the maximum value (i.e., to 1 for all the neurons). According to the authors of the Swish paper, this is what set Relu apart from the more traditional activation functions.
Third, separating Swish from Relu, the fact that it is a smooth curve means that its output landscape will be smooth. This provides benefits when optimizing the model in terms of convergence towards the minimum loss.
Fourth, small negative values are zeroed out in Relu (since f(x) = 0 for x < 0). However, those negative values may still be relevant for capturing patterns underlying the data, whereas large negative values may be zeroed out (for reasons of Sparsity, as we saw above). The Smoothness property and the values of f(x) < 0 for x ≈ 0 yield this benefit. This is a clear win over Relu.