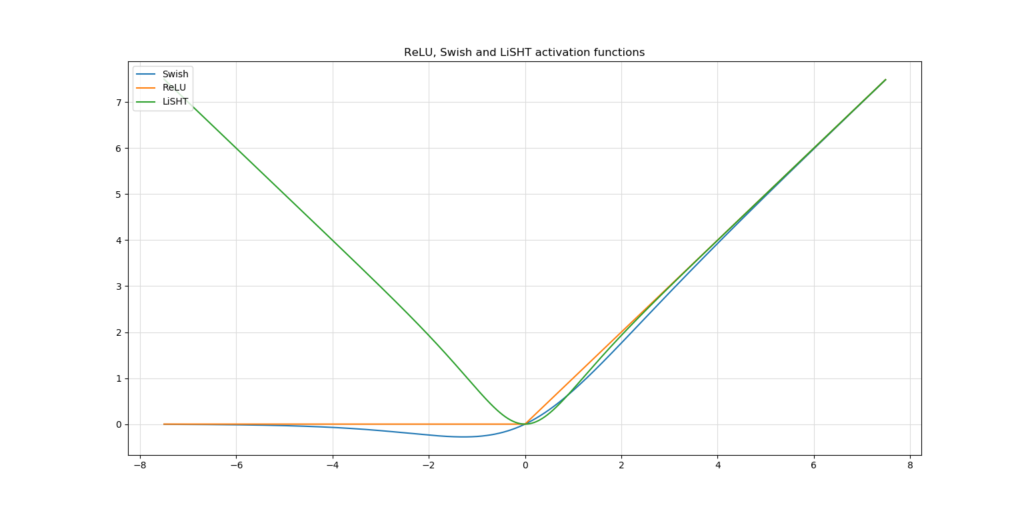
his activation function simply uses the Tanh function and scales it linearly, as follows
LiSHT(x)=x×tanh(x)
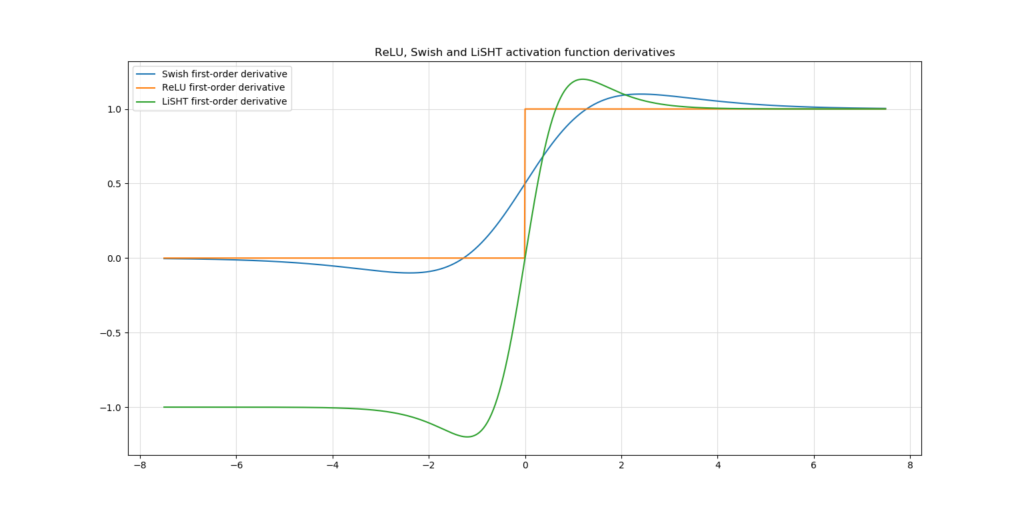
Essentially, LiSHT looks very much like Swish in terms of the first-order derivative. However, the range is expanded into the negative as well, which means that the vanishing gradient problem is reduced even further - at least in theory.
In their work, Roy et al. (2019) report based on empirical testing that indeed, the vanishing gradient problems is reduced compared to Swish and traditional Relu. Additional correlations between network learning and the shape of e.g. the LiSHT loss landscape were identified.