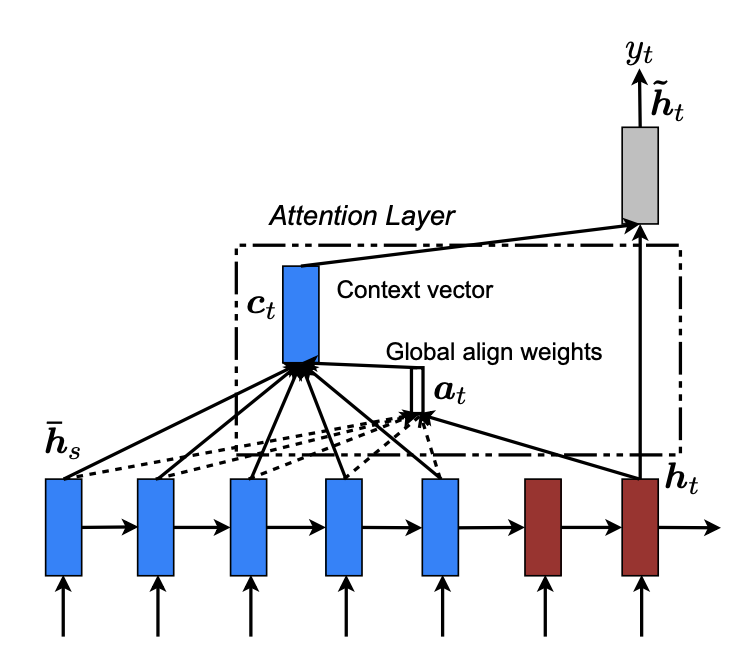
Dot Product Attention
- Luong et al., 2015
- Equivalent to Multiplicative Attention with no trainable weight matrix. Performs better at larger dimensions
- Identity matrix
- is hidden state for encoder and is hidden state for decoder
- A type of Attention Alignment
- Final scores after Softmax