- @dosovitskiyImageWorth16x162021
- paper
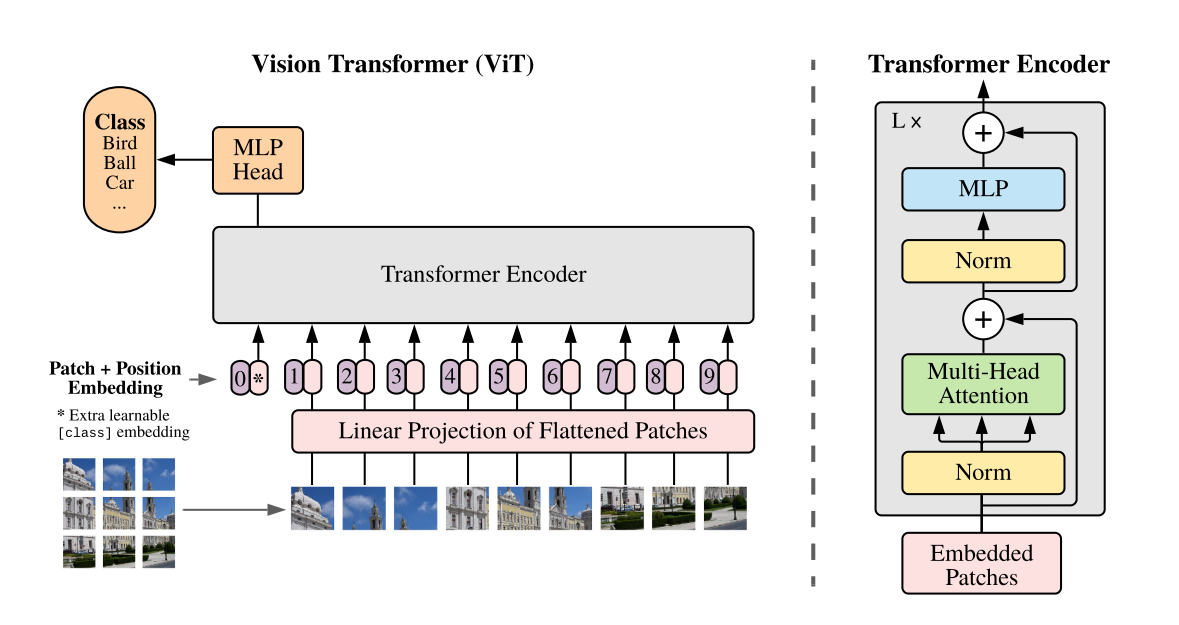
- Transformer applied directly to sequences/patches of images
- Lower computational resources
- ImageNet , CIFAR, VTAB
- Do Vision Transformers See Like Convolutional Neural Networks?
- analyzes the internal representation structure of ViTs and Conv on image classification benchmarks
- striking differences in the Features and internal structures between the two architectures
- ViT having more uniform representations across all Layers
- early aggregation of global information
- spatial localization
- discovering ViTs successfully preserve input spatial information with CLS tokens
- finding larger ViT models develop significantly stronger intermediate representations through larger pretraining datasets
- MLP-Mixer