Masked Autoencoders
- Masked Autoencoders are Scalable Vision Learners
- simple Self Supervised
- ImageNet and in Transfer Learning that an Auto Encoders —- a simple self-supervised method similar to techniques in NLP – provides scalable benefits
- mask random patches of the input image and reconstruct the missing pixels
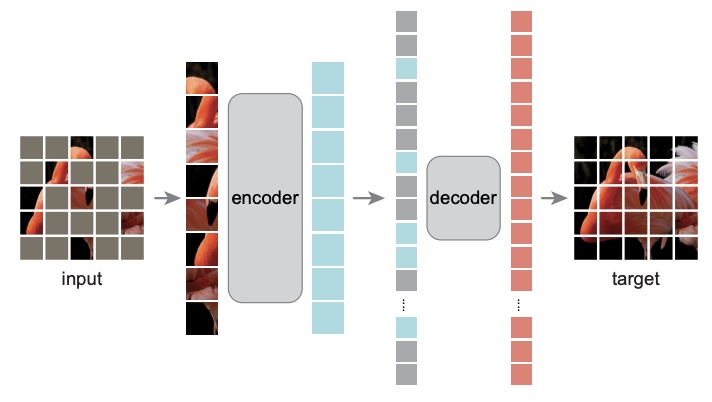
- asymmetric encoder-decoder architecture, with an encoder that operates only on the visible subset of patches (without mask tokens), along with a lightweight decoder that reconstructs the original image from the latent representation and mask tokens
- images and languages are signals of a different nature
- Images are merely recorded light without a semantic decomposition into the visual analogue of words
- The word (or subword) analog for images are pixels
- But decomposing the image into patches (like Vision Transformer reduces the quadratic computation cost of transformers compared to operating at the pixel level
- remove random patches that most likely do not form a semantic segment
- Likewise, MAE reconstructs pixels, which are not semantic entities
- hey find that masking a high proportion of the input image, e.g., 75%, yields a nontrivial and meaningful self-supervisory task
- train and throw away the decoder and fine-tune the encoder for downstream tasks
- Vanilla ViT-Huge model (ViTMAE) achieves the best accuracy
- ImageNet
- Transfer performance in downstream tasks outperforms supervised pre-training and shows promising scaling behavior
- semantics
- Occurs by way of a rich hidden representation inside the MAE