uses LSTM to compute an attention map. The feature map extracted by ResNet is input to attentive convolutional LSTM that focuses on the most salient regions of the input image to iteratively refine the predicted saliency map.
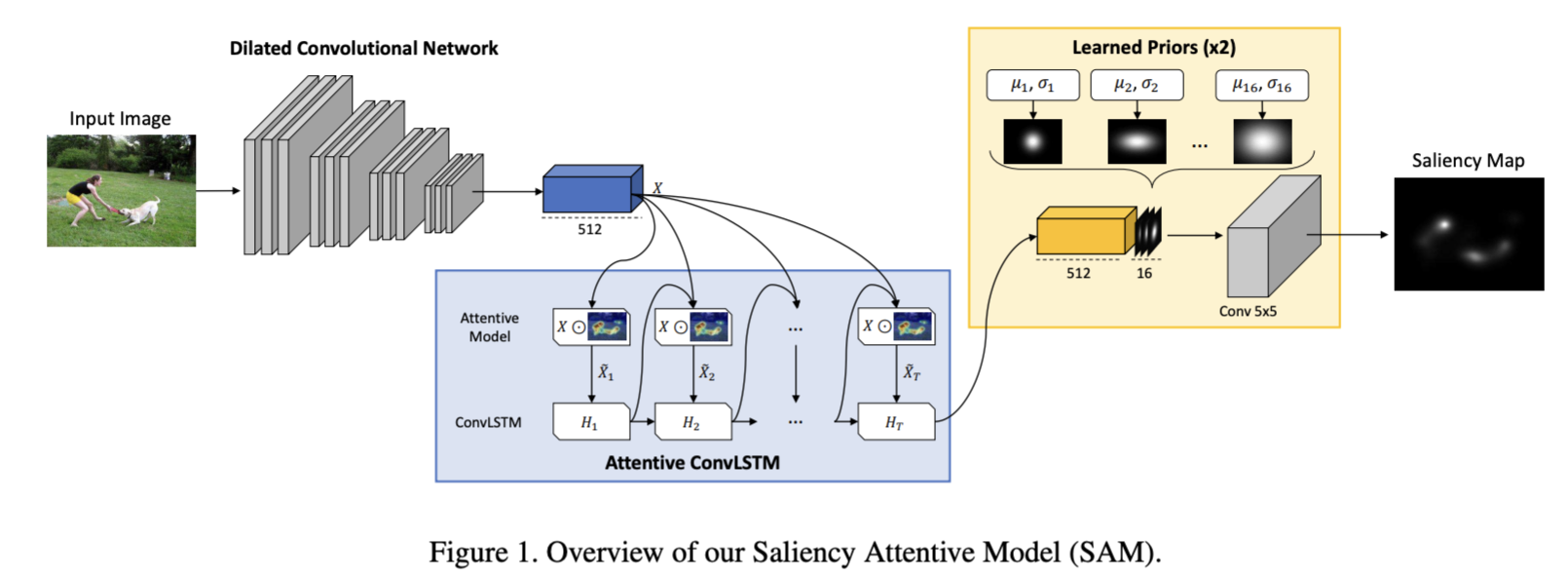
We recently proposed a Saliency Attentive Model (SAM) which, in contrast, incorporates attentive mechanisms to iteratively refine saliency predictions. Overall, it is composed by three main components: a Dilated Convolutional Network that extracts feature maps from the input image, an Attentive Convolutional LSTM which recurrently enhances saliency features and a learned prior module that incorporates the human-gaze center bias in the final predictions
Attentive Convolutional LSTM
The feature maps coming from the dilated network are then input to an Attentive Convolutional model, which recurrently process saliency features at different locations.
Moreover, we exploit the sequential nature of LSTM to process features in an iterative way. The input of the LSTM is computed, at each step, through an attentive mechanism which focuses on different regions of the image.
An attention map is generated by convolving the previous hidden state and the input (i.e. a stack of feature maps); once normalized through the softmax operator, this is applied to the input with an element-wise product
After a fixed number of iterations, the last hidden state is taken as the output of this module.
Learned Priors.
Finally, the output of the Attentive LSTM is combined with multiple learned priors which are used to model the center bias present in the human-eye fixations. Differently from existing works, which included predefined priors, we let the network learn its own priors. To reduce the number of parameters and facilitate the learning, we constraint that each prior should be a 2d Gaussian function, whose mean and covariance matrix are freely learnable. In this manner, priors are inferred purely from data,
Thanks to this strategy, the predicted saliency maps are rescaled, for both versions, by a factor of 8 instead of 32 as in the original CNNs.
In our work, we go beyond classical feed-forward networks to predict saliency maps and
propose a Saliency Attentive Model which incorporates neural attention mechanisms to iteratively refine predictions
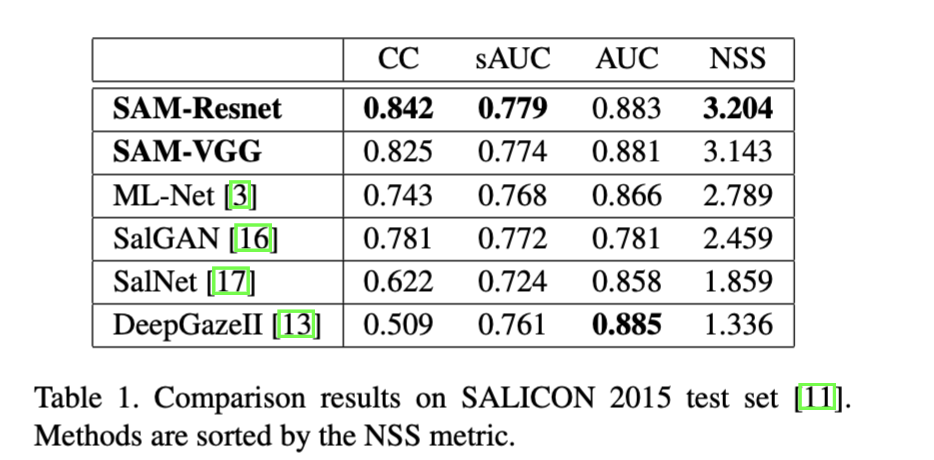
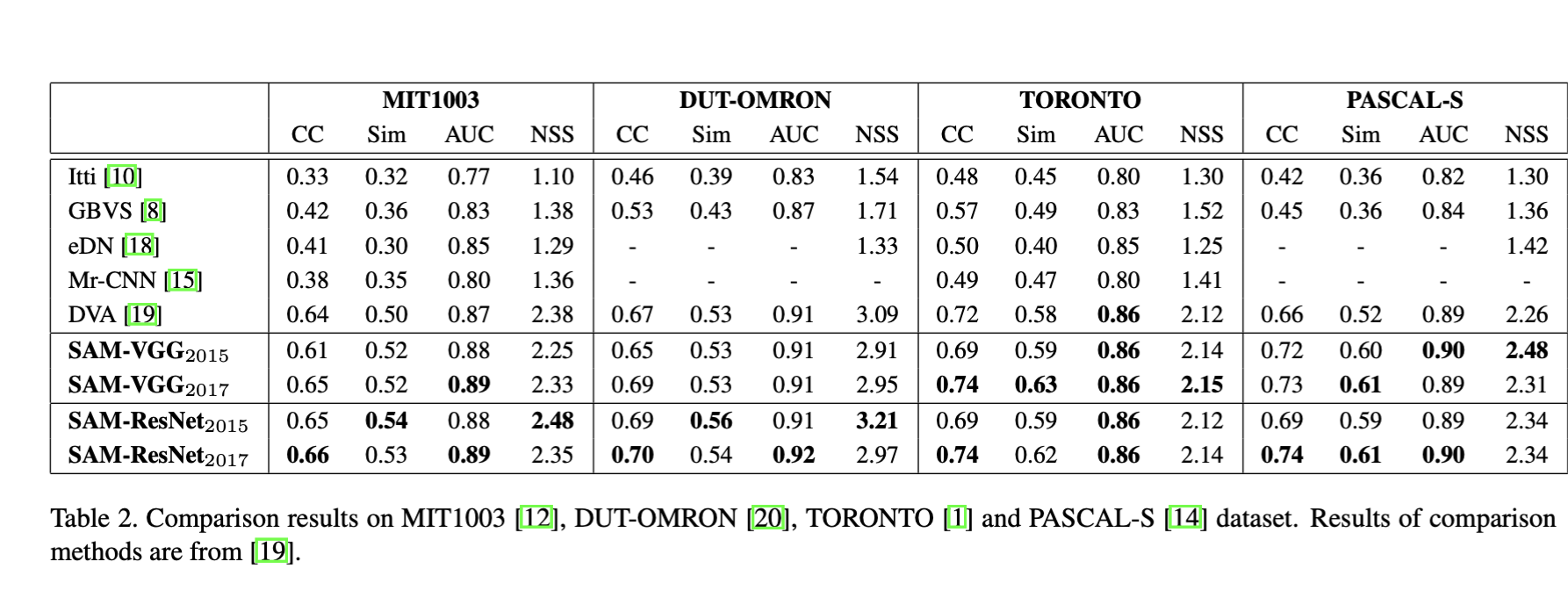
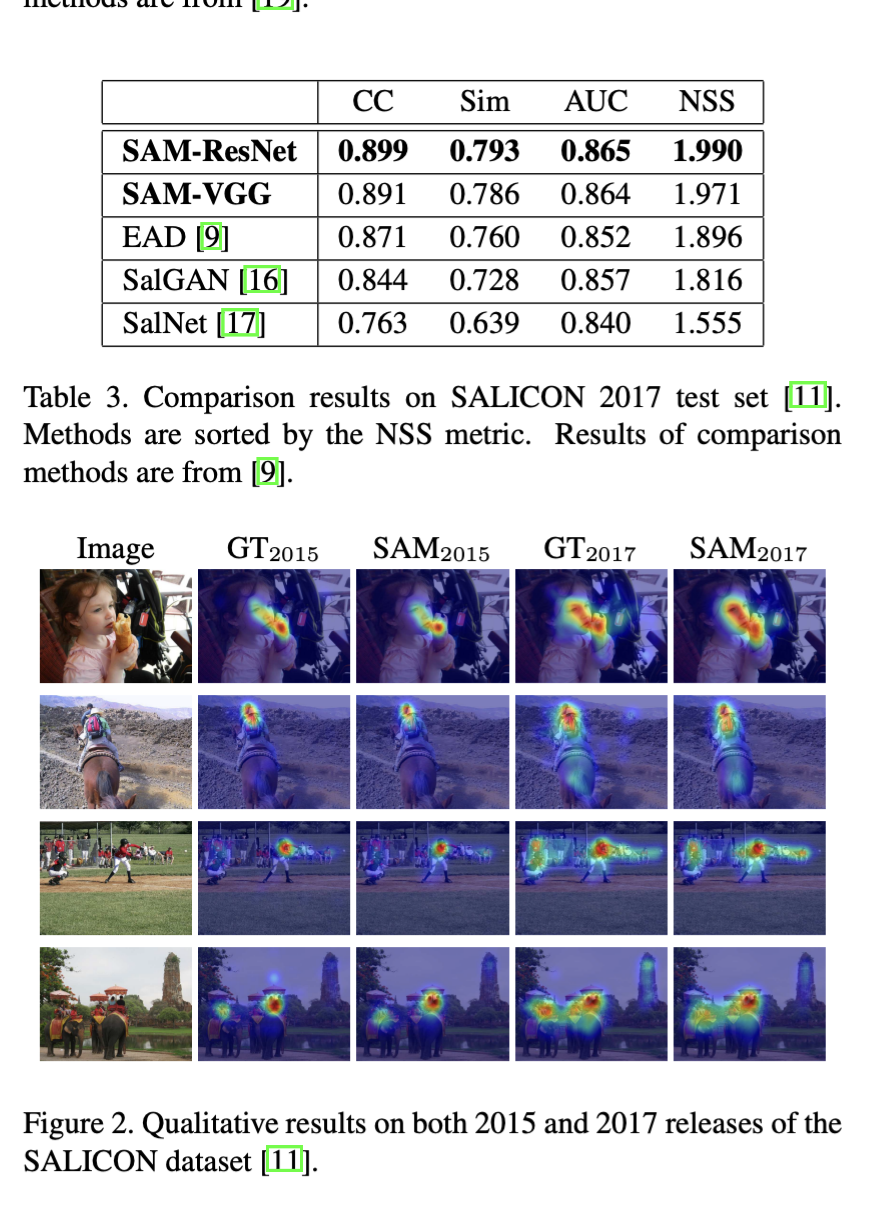
Here, we provide experimental results on other popular saliency datasets to confirm the effectiveness and the generalization capabilities of our model, which enable us to reach the state of the art on all considered datasets.
Loss Function
linear combination of three saliency evaluation metrics: the Normalized Scanpath Saliency (NSS), the Linear Correlation Coefficient (CC) and the KullbackLeibler Divergence (KL-Div)
SALICON
omposed by 20, 000 images with corresponding saliency maps computed from mouse movements