Influence of Image Classification Accuracy on Saliency Map Estimation
@oyamaInfluenceImageClassification2018.
Intro
Saliency map estimation in computer vision aims to estimate the locations where people gaze in images.
Since people tend to look at objects in images, the parameters of the model pre-trained on ImageNet for image classification are useful for the saliency map estimation
no research on the relationship between the image classification accuracy and the performance of the saliency map estimation
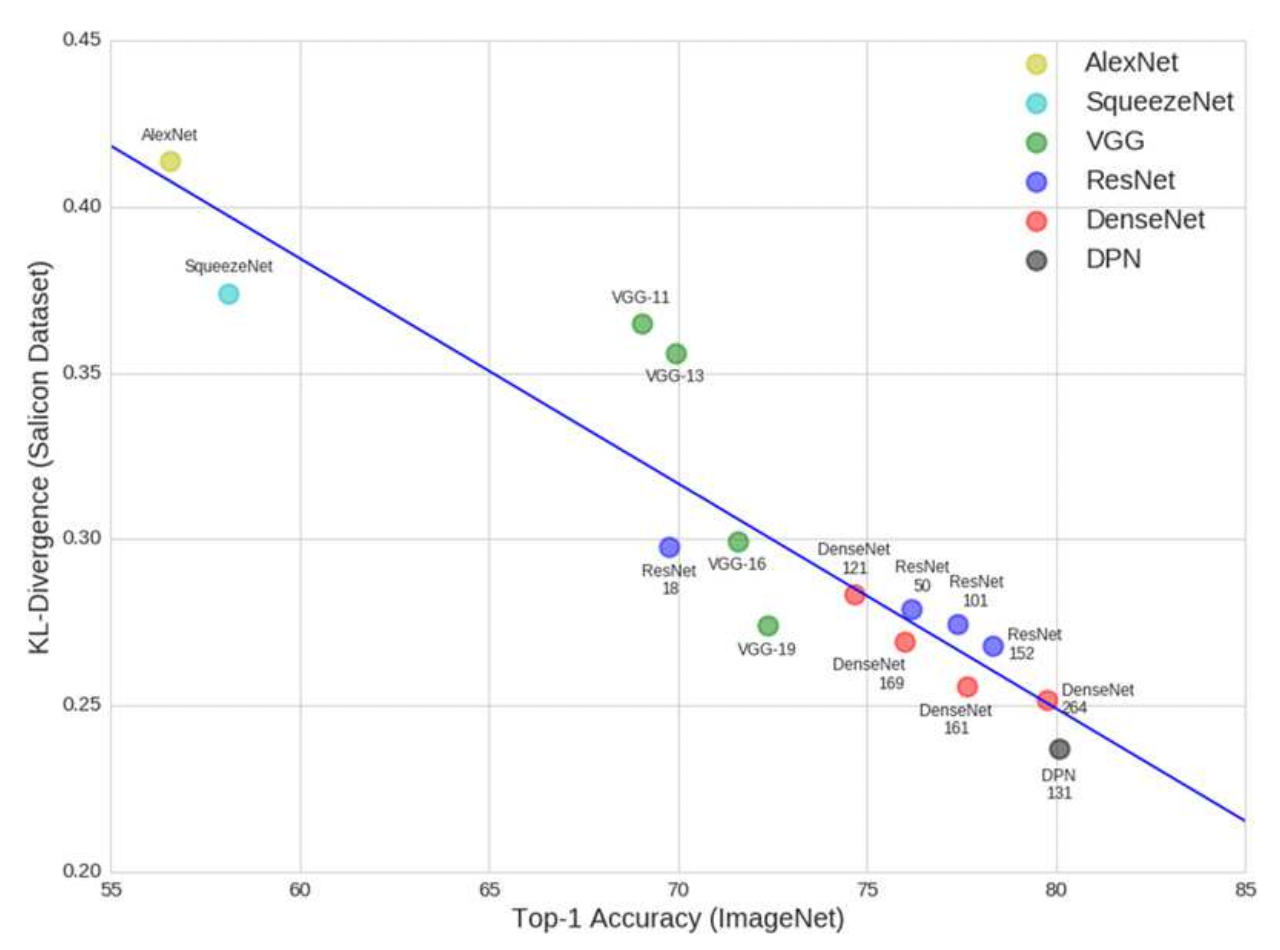
strong correlation between image classification accuracy and saliency map estimation accuracy
It the models pre-trained on ImageNet are useful for saliency map estimation the parameters of is known that
This would be because a human tends to look at the centres of objects , which are learned to be recognised in the pre-trained model for the ImageNet classification task.
Although the model based on DenseNet has achieved the state-of-the-art performance in the ACPR 2017 paper, this additional study led to even better performance using the model based on dual path networks (DPNs)
Related Work
uses the coefficients of Attention based on Information the basis Maximization (AIM) calculated by the independent component analysis (ICA) in local image patches
The distribution of the coefficients is estimated by the kernel density estimation, which is used for estimating saliency maps based on the the local patches self-information of
The operation attempts to directly minimise the reconstruction error of the input image under a Sparsity constraint on an over-complete set of feature maps
The mini-batch size and learning rate were set to 1 and 10−5 during training, respectively.
We subtract the per-channels mean value of training images from each image as pre-processing
DC
“DC is also called as transposed convolution”
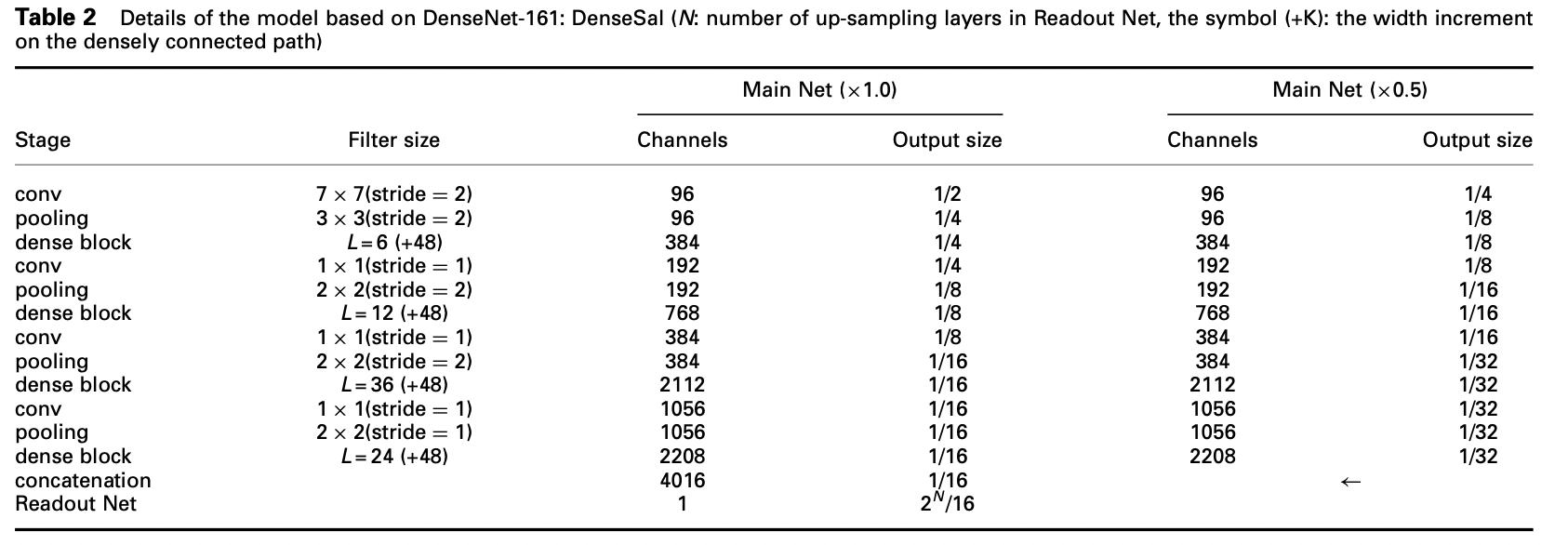
When DC is used for the up-sampling layers in Readout Net, the first, second, and third DC followed by a ReLU layer in Readout Net reduce the channels to 128, 64, and 32, respectively. Then, the 1 × 1 convolution reduces the channel to 1 to predict the saliency map. The filter size of DC was set to 4 × 4.
method to recover a high-resolution image from its additional low resolution counterpart with little computational cost, by rearranging the data along the channel into feature maps with a convolution operation.
SPC
When SPC is used for the up-sampling layers, each SPC layer reduces the channels to one forth, followed by a 3 × 3 convolution and a ReLU layer. Then, the 1 × 1 convolution predicts the saliency map from the output of the last SPC layer.
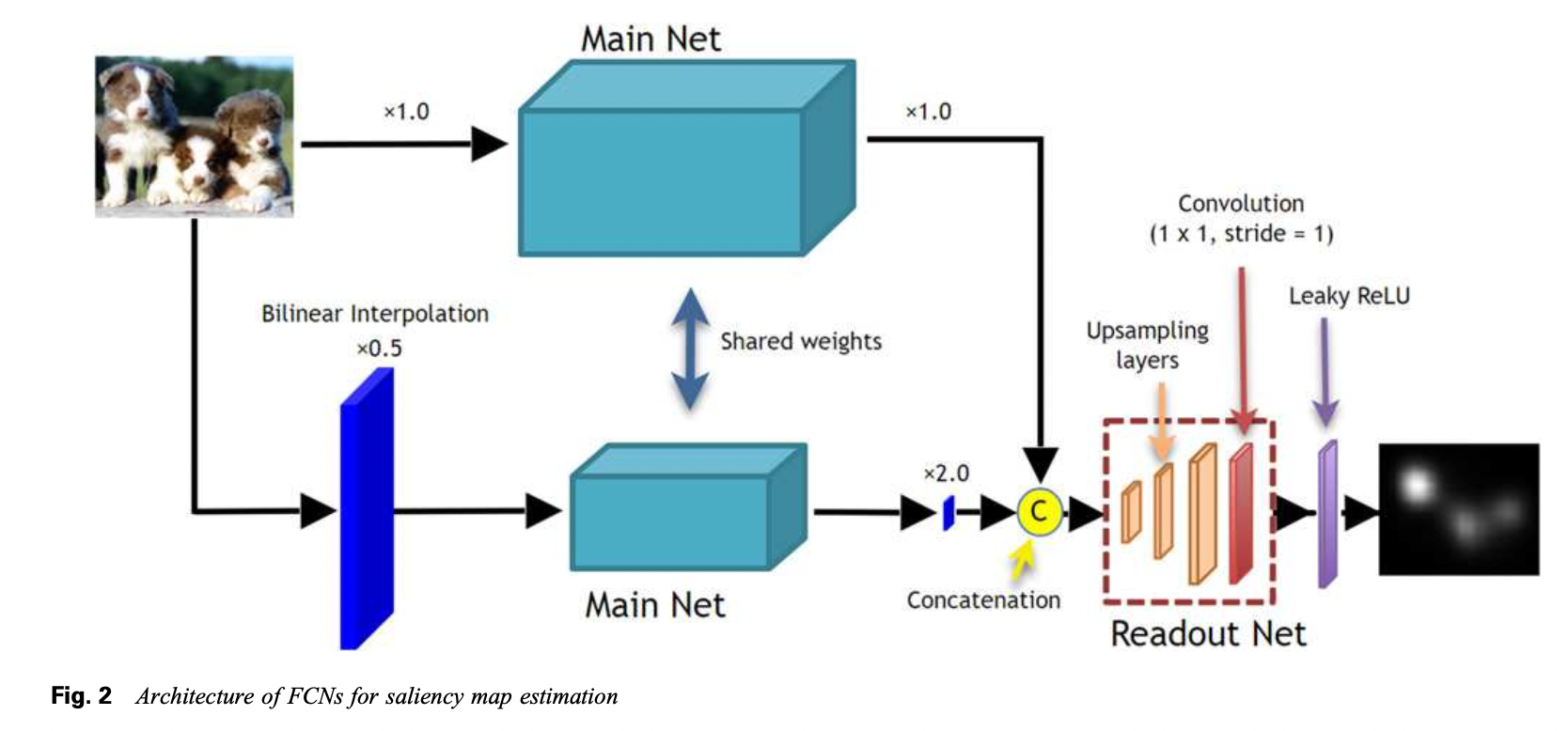
each BI layer in the up-sampling network resizes a feature map twice while maintaining the feature-map channels, GPU was out of memory when three up-sampling layers were used for all channels of outputs of Main Net
BI
the order of up-sampling and projection (1 × 1 convolution) can be inverted without any influence on the output
the concatenated feature maps from Main Nets are first processed by the 1 × 1 convolution to output feature map, followed by the BI up-sampling layers. the 1-channel
strong correlation between image classification accuracy and saliency map estimation accuracy.
not only the architecture but also the initialisation strategy using the weights pre-trained with the ImageNet classification task were important for estimating the saliency maps
model which is pre-trained with the ImageNet classification and has achieved high
“for performance on the classification task is also useful the”
“saliency map estimation task”
human fixations often concentrate on objects in the image, while the model pre-trained on ImageNet can react on many objects in images because ImageNet has a wide variety of object categories.
If the model is initialised with random weights and is trained on a fixation dataset with the limited categories of objects for saliency map estimation, to the objects in the training dataset the model would overfit
if the model is trained for the image classification task which includes a wide variety of categories, overfitting for the objects in the training dataset would be suppressed owing to a large number of categories.
 {:height 598, :width 600}
{:height 598, :width 600}