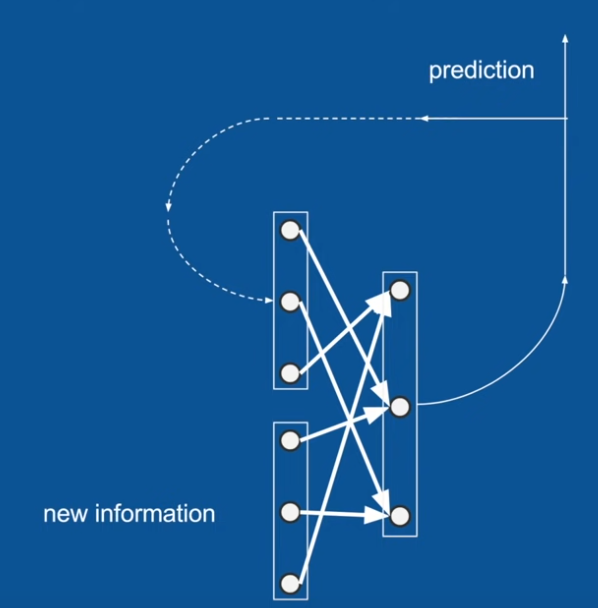
Recurrent
- Sequences as inputs/outputs
- Sequential processing
- Turing complete
- memory through state persisted between timesteps
- operation invariant to the sequence
- reduces no of params needed
- Output comes back as input
- variable sized inputs and outputs : encoder decoder
- Three weight matrices and two bias vectors.
- ht=σh(Whhht−1+Wxhxt+bh)
- yt=σy(Whyht+by)
- Stateful : hidden state kept across batches of inputs
- Activation usually Sigmoid or Tanh
- BPTT
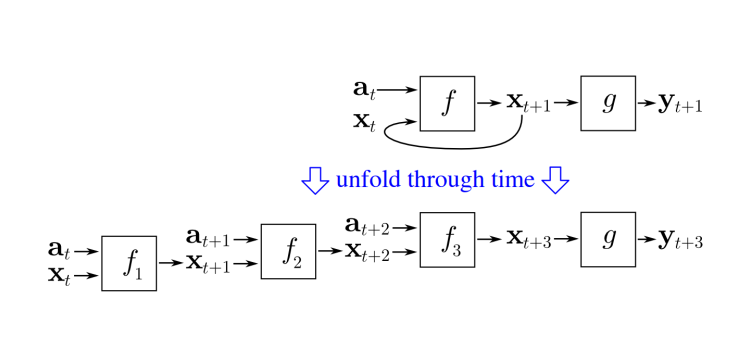
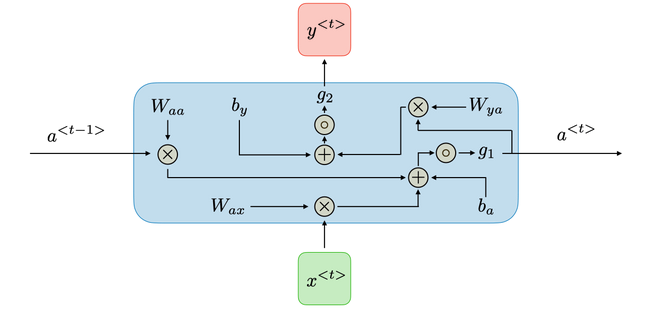
- architecture
- If eigen decomposition W=Q∧tQ, then ht=QT∧tQ
- If less than 0 then will converge to 0 or if bigger then will explore to infinity → long sequences
- Element wise clippingdeeplearning
- CLIP if bigger than value
- Norm clipping
- CLIP if $$||g|| >vsetg = \frac{gv}{||g||}$
- v can be decided by trial and error
- Training stuff
- Softmax but on every output vector simultaneously
- If Softmax is lower (eg between 0 and 0.5). It becomes more confident and hence more conservative
- Near 0 is very diverse and less confident
- Feed a char into the RNN → distribution over characters that comes next → Sample from it → Feed it back
- Some basic patterns from here
- The model first discovers the general word-space structure and then rapidly starts to learn the words.
- First starting with the short words and then eventually the longer ones.
- Topics and themes that span multiple words (and in general longer-term dependencies) start to emerge only much later.