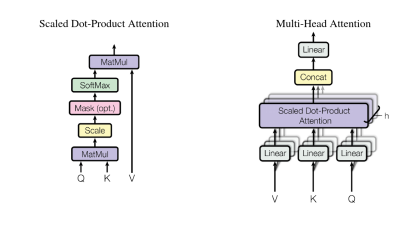
which computes self-Attention over the inputs, then adds back the residual and layer normalizes everything. The Attention head can be split into multiple segments, hence the name multi-head
Multiple Attention instances, each focusing on a different part of the input
Words can mean different things in context
If using Self Attention, then this just gets summed up. Which is not very nice
Several Attention heads → different output vectors
Concatenate them and pass through a linear transform → dimension back to k