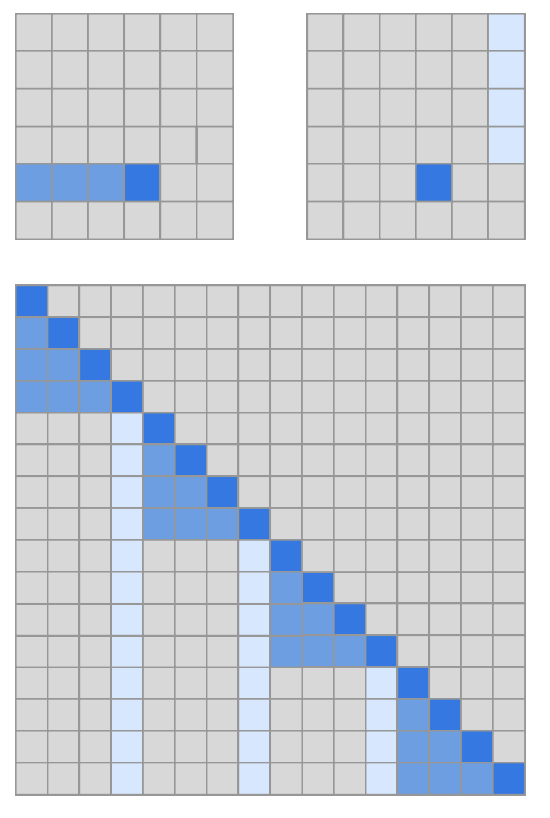
Fixed Factorization Attention paper Specific cells summarize previous locations and propagate to all future cells. Part of Sparse Transformer Fixed Attention pattern with c = 1 limits expressivity many representations in the network are only used for one block whereas a small number of locations are used by all blocks. Choosing $c \in Strided Attention when using multiple heads, having them attend to distinct subblocks of length c within the block of size l was preferable to having them attend to the same subblock