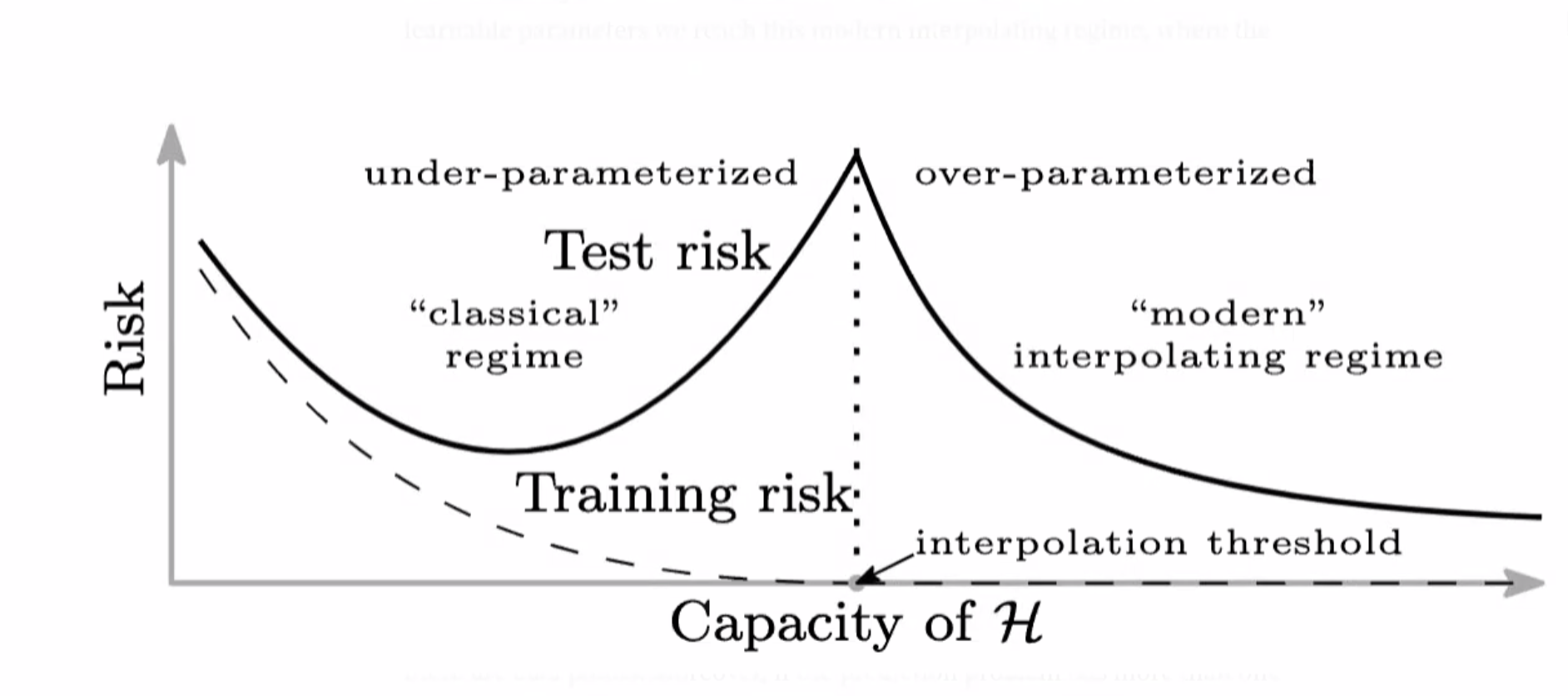
When increasing the model size or the number of epochs, performance on the test set initially improves, then worsens but then again starts to improve and finally saturates.
This phenomena is against conventional wisdom, because the test error should not be decreasing again after increasing.
occurs often in the over-parameterization regime
models which have a lot of parameters
models that have huge complexity
once the model has enough capacity to drive the training loss to near zero, the model fits the training data almost perfectly
This implies that further capacity cannot help the model fit the training data any better; any change must occur between the training points
It’s certainly true that as we add more capacity to the model, it will have the capability to create smoother functions. Figures 8.11b–f show the smoothest possible functions that still pass through the data points as we increase the number of hidden units. When the number of parameters is very close to the number of training data examples (figure 8.11b), the model is forced to contort itself to fit the training data exactly, resulting in erratic predictions. This explains why the peak in the double descent curve is so pronounced. As we add more hidden units, the model has the ability to construct smoother functions that are likely to generalize better to new data.
First, the network initialization may encourage smoothness, and the model never departs from the sub-domain of smooth function during the training process. Second, the training algorithm may somehow “prefer” to converge to smooth functions