AdamW
- @loshchilovDecoupledWeightDecay2019
Adam Features
-
why use the same learning rate for every parameter, when we know that some surely need to be moved further and faster than others
-
Since the square of recent gradients tells us how much signal we’re getting for each weight, we can just divide by that to ensure even the most sluggish weights get their chance to shine
-
with a little tweak to keep early batches from being biased
-
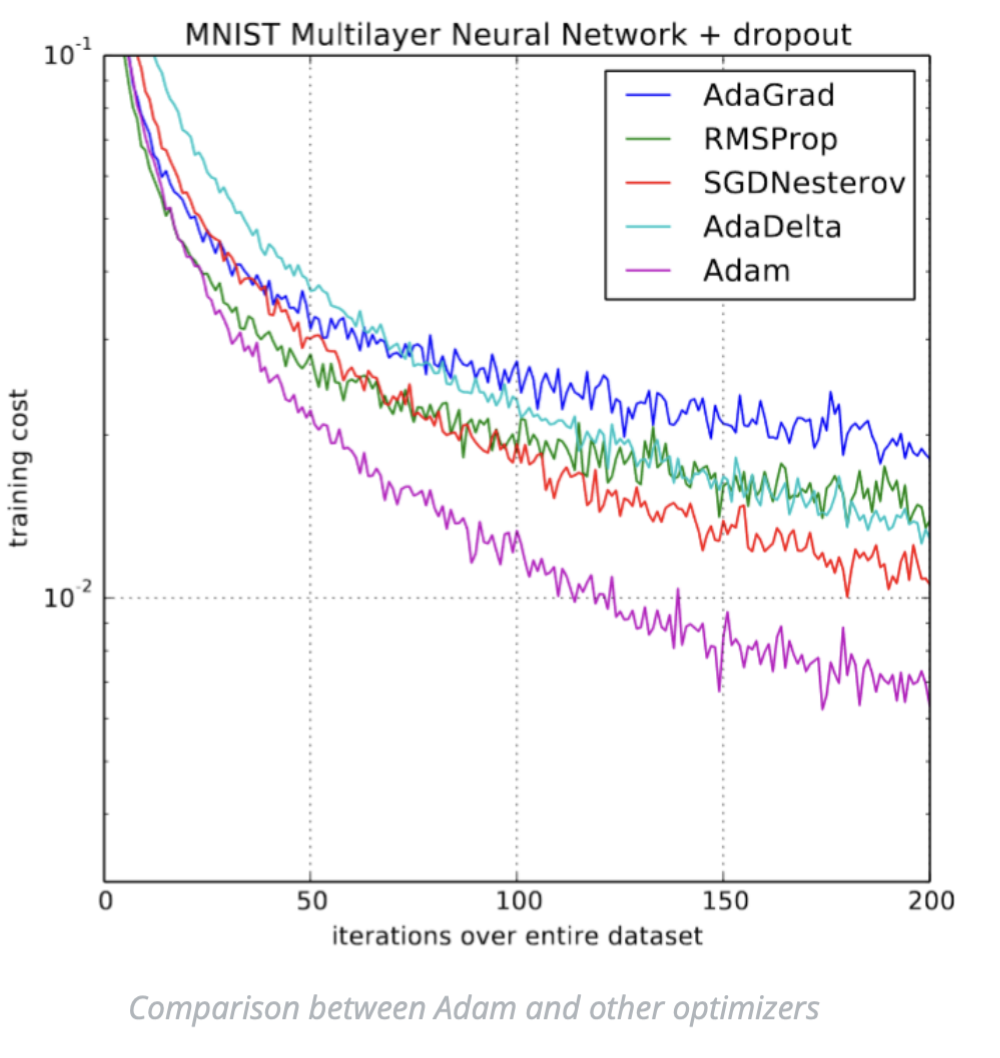
Few research articles used it to train their models, new studies began to clearly discourage to apply it and showed on several experiments that plain ole SGD with momentum was performing better.
-
-
-
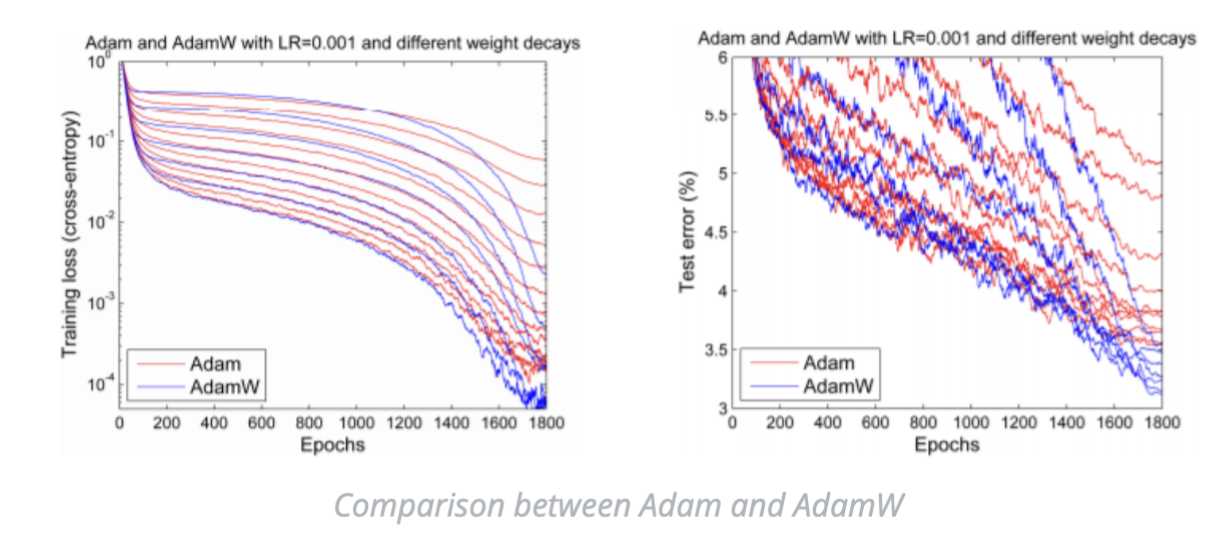
Ilya Loshchilov and Frank Hutter pointed out in their paper that the way weight decay is implemented in Adam in every library seems to be wrong, and proposed a simple way (which they call AdamW) to fix it
-
PhD student Jeremy Bernstein has pointed out that the claimed convergence problems are actually just signs of poorly chosen hyper-parameters, and that perhaps amsgrad won’t fix things anyway. Another PhD student, Filip Korzeniowski, showed some early results that seemed to support this discouraging view of amsgrad.