ALBERT
- Lite BERT
- blog #Roam-Highlights
- perhaps even better when scaled to the same number of parameters as BERT
- Factorized Embedding Parameters
- cross-layer parameter sharing
- inter-sentence coherence loss
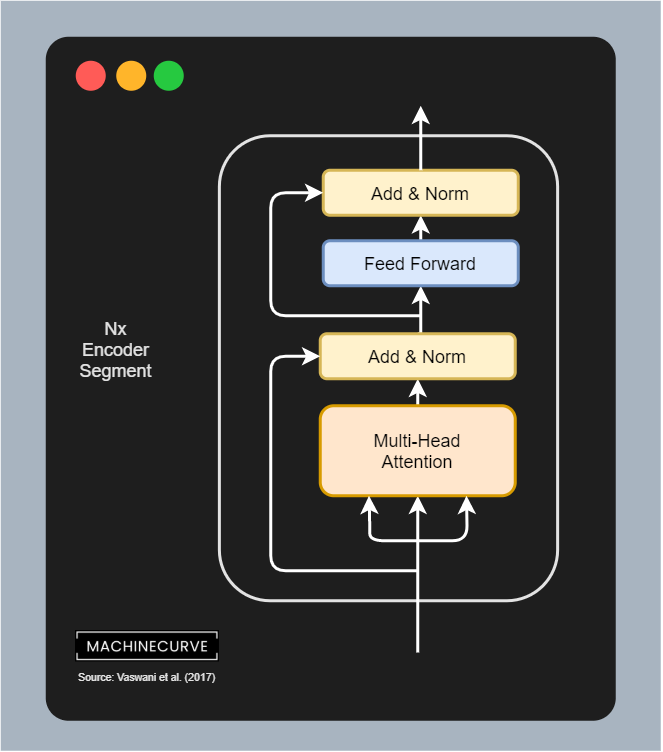
- We can see that the ALBERT base model attempts to mimic BERT base, with a hidden state size of 768, parameter sharing and a smaller Embedding size due to factorization explained above. Contrary to the 108 million parameters, it has only 12 million. This makes a big difference when training the model.
- Another model, ALBERT xxlarge (extra-extra large) has 235 million parameters, with 12 encoder segments, 4096-dimensional hidden state and 128-dimensional Embedding size. It also includes parameter sharing.
- GLUE
- SQuAD
- RACE
- For Factorized Embedding Parameters, the authors report good performance. Both the case where cross-layer parameters were not shared and where they were, are reported. Without sharing, larger Embedding sizes give better performance. With sharing, performance boosts satisfy at an Embedding size of 128 dimensions. That’s why the 128-size embeddings were used in the table above.
- For cross-layer parameter sharing, the authors looked at not performing cross-layer sharing, performing cross-layer sharing for the feedforward segments only, performing sharing for the Attention segments, and performing sharing for all subsegments. It turns out that sharing the parameters for the Attention segments is most effective, while sharing the feedforward segment parameters does not contribute significantly. This clearly illustrates the important role of the Attention mechanism in Transformer models. Because, however, all-segment sharing significantly decreases the number of parameters, at only slightly worse performance compared to Attention-only sharing, the authors to perform all-segment sharing instead.
- For the SOP task, we can read that if NSP is performed on a SOP task, performance is poor. NSP on NSP of course performs well, as well as SOP on SOP. However, if SOP is performed on NSP, it performs really well. This suggests that SOP actually captures sentence coherence whereas NSP might not, and that SOP yields a better result than NSP.