-
Unbiased Look at Dataset Bias
-
Unbiased Look at Dataset Bias
-
Alexei A. Efros Antonio Torralba
-
[@Unbiased look at dataset bias](@Unbiased look at dataset bias.md)
-
Abstract
-
some datasets, that started out as data capture efforts aimed at representing the visual world, have become closed worlds unto themselves
-
despite the best efforts of their creators, the datasets appear to have a strong buildin bias
-
Of course, much of the bias can be accounted for by the divergent goals of the different datasets: some captured more urban scenes, others more rural landscapes; some collected professional photographs, others the amateur snapshots from the Internet; some focused on entire scenes, others on single objects, etc
-
Caltech has a strong preference for side views, while ImageNet is into racing cars; PASCAL have cars at noncanonical view-points; SUNS and LabelMe cars appear to be similar, except LabelMe cars are often occluded by small objects, etc
-
Name That Dataset
-
Measuring Dataset Bias
-
settle for a few standard checks, a diagnostic of dataset health if you will.
-
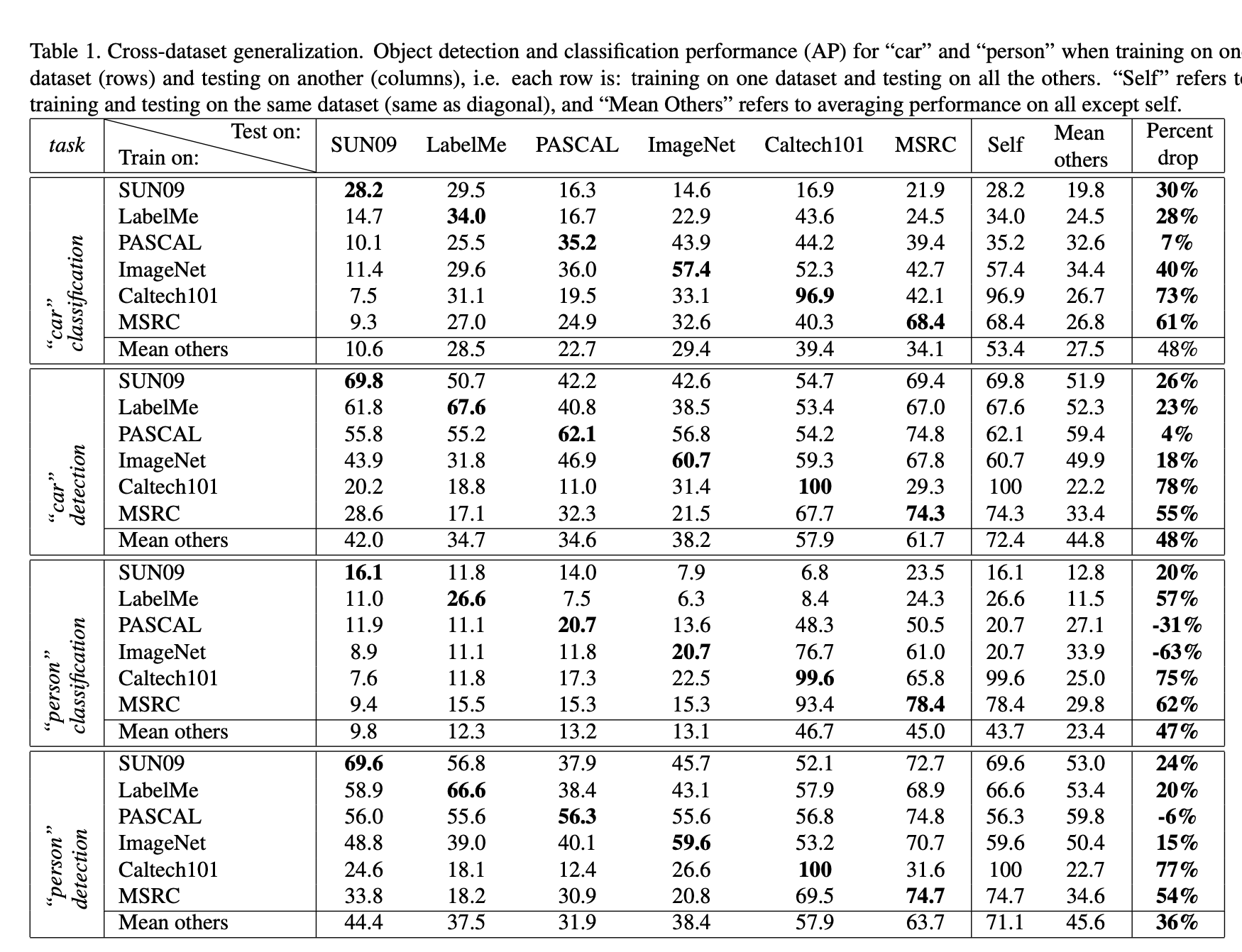
[Cross-dataset generalization](Cross-dataset generalization.md)
-
[Selection bias](Selection bias.md)
-
[Capture bias](Capture bias.md)
-
[Label bias](Label bias.md)
-
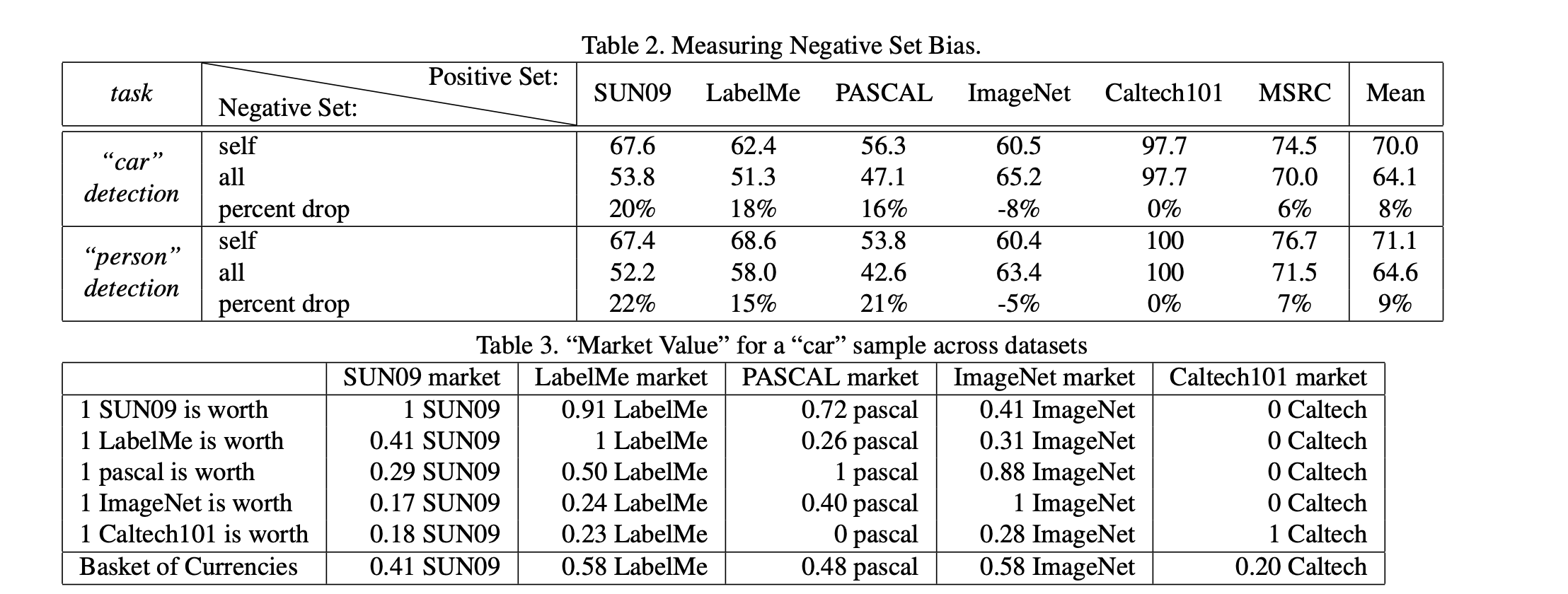
[Negative Set Bias](Negative Set Bias.md)
-
Measuring Dataset’s Value
-
two basic ways of improving the performance
-
The first solution is to improve the features, the object representation and the learning algorithm for the detector.
-
The second solution is to simply enlarge the amount of data available for training.
-
So, what is the value of current datasets when used to train algorithms that will be deployed in the real world? The answer that emerges can be summarized as: “better than nothing, but not by much”.
-
Discussion
-
that the reason is not that datasets are bad, but that our object representations and recognition algorithms are terrible and end up over-learning aspects of the visual data that relates to the dataset and not to the ultimate visual task.
-
In fact, a human learns about vision by living in a reduced environment with many potential local biases and yet the visual system is robust enough to overcome this.
-
Should we care about the quality of our datasets? If the goal is to reduce computer vision to a set of feature vectors that can be used in some machine learning algorithm, then maybe not. But if the goal is to build algorithms that can understand the visual world, then, having the right datasets will be crucial.
-
Images
-
-