The Elephant in the Interpretability Room
- @bastingsElephantInterpretabilityRoom2020
Intro
- While attention conveniently gives us one weight per input token and is easily extracted, it is often unclear toward what goal it is used as explanation.
- that often that goal, whether explicitly stated or not, is to find out what input tokens are the most relevant to a prediction, and that the implied user for the explanation is a model developer
- For this goal and user, we argue that input saliency methods are better suited, and that there are no compelling reasons to use attention, despite the coincidence that it provides a weight for each input.
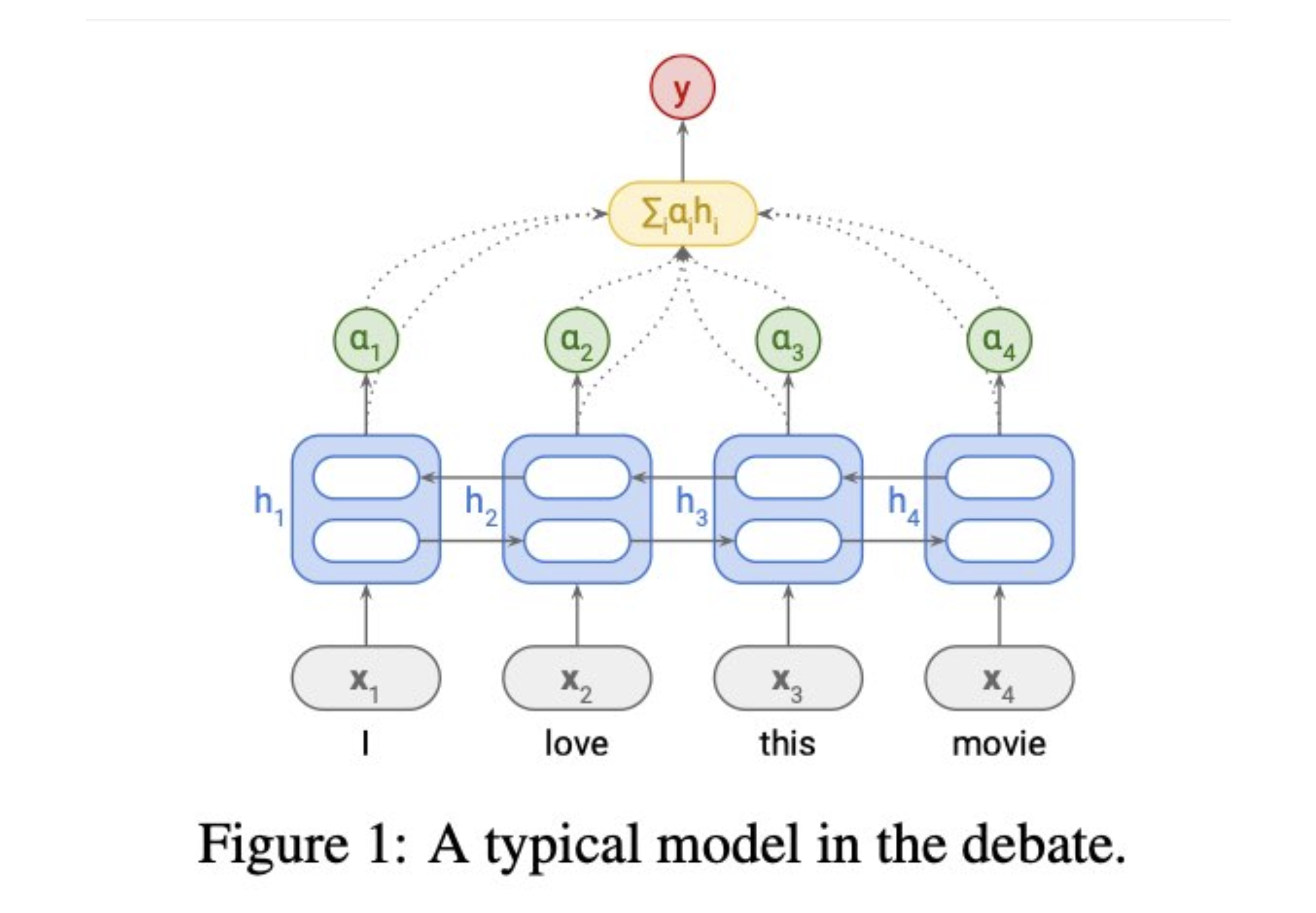
The Attention Debate
- summarize the debate on whether attention is explanation
- mostly features simple BiLSTM text classifiers
- Unlike Transformers (Vaswani et al., 2017), they only contain a single attention mechanism, which is typically MLP-based (Bahdanau et al., 2015)

Is Attention (not) Explanation?
- Jain and Wallace (2019) show that attention is often uncorrelated with gradientbased feature importance measures, and that one can often find a completely different set of attention weights that results in the same prediction
- Serrano and Smith (2019) find, by modifying attention weights, that they often do not identify those representations that are most most important to the prediction of the model
- Finally, Pruthi et al. (2020) propose a method to produce deceptive attention weights. Their method reduces how much weight is assigned to a set of ‘impermissible’ tokens, even when the models demonstratively rely on those tokens for their predictions.
Was the Right Task Analyzed
- the performance of an NMT model degrades substantially if uniform weights are used, while random attention weights affect the text classification performance minimally.
- even for the task of MT, the first case where attention was visualized to inspect a model (§1), Ding et al. (2019) find that saliency methods (§3) yield better word alignments.
Can Attention Be Improved
-
Mohankumar et al. (2020) observe high similarity between the hidden representations of LSTM states and propose a diversity-driven training objective that makes the hidden representations more diverse across time steps
-
using representation erasure that the resulting attention weights result in decision flips more easily as compared to vanilla attention
-
Deng et al. (2018) propose variational attention as an alternative to the soft attention of Bahdanau et al. (2015), arguing that the latter is not alignment, only an approximation thereof
-
additional benefit of allowing posterior alignments, conditioned on the input and the output sentences.
-
[Saliency vs Attention](Saliency vs Attention.md)
Attention is not not Interesting
- Voita et al. (2019) and Michel et al. (2019) analyze the role of attention heads in the Transformer architecture and identify a few distinct functions they have, and Strubell et al. (2018) train attention heads to perform dependency parsing, adding a linguistic bias
- Strout et al. (2019) demonstrate that supervised attention helps humans accomplish a task faster than random or unsupervised attention
Beyond Saliency
- counterfactual analysis might lead to insights, aided by visualization tools (Vig, 2019; Hoover et al., 2020; Abnar and Zuidema, 2020)
- The DiffMask method of DeCao et al. (2020) adds another dimension: it not only reveals in what layer a model knows what inputs are important, but also where important information is stored as it flows through the layers of the mode
Limitations of Saliency
- changes in the predicted probabilities may be due to the fact that the corrupted input falls off the manifold of the training data (Hooker et al., 2019)
- a drop in probability can be explained by the input being OOD and not by an important feature missing
- at least some of the saliency methods are not reliable and produce unintuitive results (Kindermans et al.
-
- or violate certain axioms (Sundararajan et al., 2017).
- A more fundamental limitation is the expressiveness of input saliency methods
- Obviously, a bag of per-token saliency weights can be called an explanation only in a very narrow sense
- One can overcome some limitations of the flat representation of importance by indicating dependencies between important features (for example, Janizek et al. (2020) present an extension of IG which explains pairwise feature interactions) but it is hardly possible to fully understand why a deep non-linear model produced a certain prediction by only looking at the input tokens