Predicting University Students’ Exam Performance Using a Model-Based Adaptive Fact-Learning System
Literature
Digital learning systems allow learners to track their progress and make study decisions informed by data1.
For example, Duolingo, a language- learning tool, shows learners an overview of their mastery of each lesson in a dashboard (Figure 1(a) in Settles & Meeder, 2016). Rosetta Stone, another language-learning tool, has a similar dashboard and includes a suggested next study activity (Ridgeway, Mozer, & Bowles, 2017).
Adaptive learning systems take this a step further by assuming control over some study choices that might otherwise be made by learners. Using an internal model of the learner that is informed by the learner’s performance, such systems can adapt the learning experience in real time (VanLehn, 2006).
The adaptation can include changing the difficulty of the problems presented to the learner, changing the amount of feedback that the learner receives, and changing the scheduling of repetitions within and between learning sessions
What type and degree of adaptivity are most beneficial is an empirical question and depends on whether the adaptive system accurately traces the acquisition and forgetting of knowledge over time. If implemented well, adaptive learning systems can help students achieve more effective study behaviour by facilitating spaced repetition, active study, and other effective techniques.
SlimStampen: A Model-Based Adaptive Fact-Learning System App
Following correct answers, the next trial commenced after one second. For incorrect answers, feedback remained on the screen until the learner pressed the “Next” button at the bottom of the screen (see Figures 1b and 1d), making the feedback similar to the study trials.
Scheduling Algorithm
extension of the adaptive item-learning model by Pavlik and Anderson (2005; 2008) and has been tested in laboratory settings (van Rijn, van Maanen, & van Woudenberg, 2009; Sense, Behrens, Meijer, & van Rijn, 2016; Sense, Meijer, & van Rijn, 2018) but has not been deployed in a university course before.
his model capitalizes on the spacing effect (see Dempster, 1988, for a review) within a single session by scheduling repetitions as far apart as possible, while also
optimizing for the testing effect (see van den Broek et al., 2016, for a review) by repeating items soon enough that most responses are correct.
The model represents every encountered item by a unique memory chunk, based on the ACT-R theory of declarative memory (Anderson, 2007).
Each chunk has an activation—a representation of the ease with which that item could be retrieved—that receives a boost whenever an item is re-encoded and that decays over time
The activation A of a chunk i at time t, given n previous encounters at t1,…,tn seconds ago, is
Ai(t)=ln(Σj=1ntj−di(t)
di(t)=c∗eAi(tn−1)+αi
When a new trial commences, the model determines the activation of all items 15 seconds in the future, and if the item with the lowest activation has an activation value below a retrieval threshold, that item will be scheduled for presentation
If all predicted activations are above the retrieval threshold, the model will introduce a new item
y selecting items on the basis of their activation, items will be repeated with as much spacing as possible, while ensuring that, theoretically, a correct response can still be given.
The decay of the activation (parameter d in Equation (1)) varies between items to account for differences in difficulty. The higher this decay, the faster a chunk’s activation will decrease, causing it to be repeated sooner than an item with a lower decay.
The decay d of a chunk i at time t depends on the activation of the chunk at the time of its previous encounter, as well as an offset that we label the rate of forgetting, α
The model assumes that each item has a standard initial rate of forgetting when it is first presented. However, this value is updated during learning
At each presentation, the model calculates an expected response time, E(RT ), based on the activation at the time of the presentation (e−Ai , based on Equation (5) in Anderson, Bothell, Lebiere, & Matessa, 1998) and an estimated reading time of the prompt (based on the number of characters in the prompt; see Section 2.2.1 in Nijboer, 2011, for details).
The accuracy of the response and the mismatch between expected and observed response time are used to update the value of the rate-of-forgetting parameter.
Using both accuracy and response time to update the model allows for adjustment of the parameter estimate after any response, not just after an incorrect response.
A correct but slower-than-expected response signals that the [memory trace](memory trace.md) has decayed further than assumed, meaning that the item’s true rate of forgetting is higher than the current estimate.
That is, when a learner arrives at the right answer but takes longer than anticipated, they likely struggled to Recall the information
Conversely, an incorrect or missing response suggests that the activation of the
item’s [memory trace] actually dropped below the retrieval threshold, which means that the true rate of forgetting should be higher because this item’s activation was expected to be above the threshold (which was fixed at [ACT-R](memory trace] actually dropped below the retrieval threshold, which means that the true rate of forgetting should be higher because this item’s activation was expected to be above the threshold (which was fixed at [ACT-R.md)’s default value).
An unexpectedly fast correct response, on the other hand, indicates a stronger- than-expected [memory trace](memory trace.md) and implies that the estimated rate of forgetting should be adjusted downward.
Since interruption or distraction can cause disproportionately large response times, observed response times are capped before their mismatch with the expected response time is calculated.
To update the rate of forgetting after each trial, the model uses a binary search in a small window around the previous value to identify the rate of forgetting that minimizes the mismatch between E(RT) and RT′
Usage of the System
Most students exhibited strong “cramming” behaviour, with much higher SlimStampen usage in the days leading up to the exam: in both cohorts, we observed a sharp increase in activity starting around 10 days before the exam and peaking on the last day. As the exam neared, usage intensified throughout the day and extended into the night.
Exam Performance
In both cohorts, students that used SlimStampen (92.6% of students) obtained higher grades than those that did not—averaging 6.91 compared to 5.86, respectively
a direct comparison of these groups is problematic due to selection effects and the imbalanced distributio
Amount of Practice
number of study trials completed was positively correlated with the final grade completing more trials was associated with higher grades on the exam
The number of unique days on which a learner engaged with the tool—an index of spaced practice—was also positively correlated with exam grades (r = 0.27, t(283) = 4.81, p < 0.001)
the two measures of engagement were strongly and positively correlated (r = 0.75, t(283) = 18.78, p < 0.001).
Studied Versus Non-studied Items
We observed a large difference between exam questions that learners had used the system to study and questions that they had not3: students’ accuracy was 83.7% on studied items but only 53.6% on unstudied items
A mixed-effects logistic regression (with random intercepts for learners and items) confirmed that encountering an item during SlimStampen rehearsal considerably increased the chances of a correct answer on the exam (bstudied/not studied = 1.70, SE = 0.18, z = 9.06, p < 0.001).
Rates of Forgetting and Grades
The rate of forgetting, which was initially estimated for each learner–item combination, was converted into a learner-specific rate of forgetting by averaging over all studied items
The negative correlation shows that a learner who was estimated to forget material more slowly also tended to obtain higher grades.
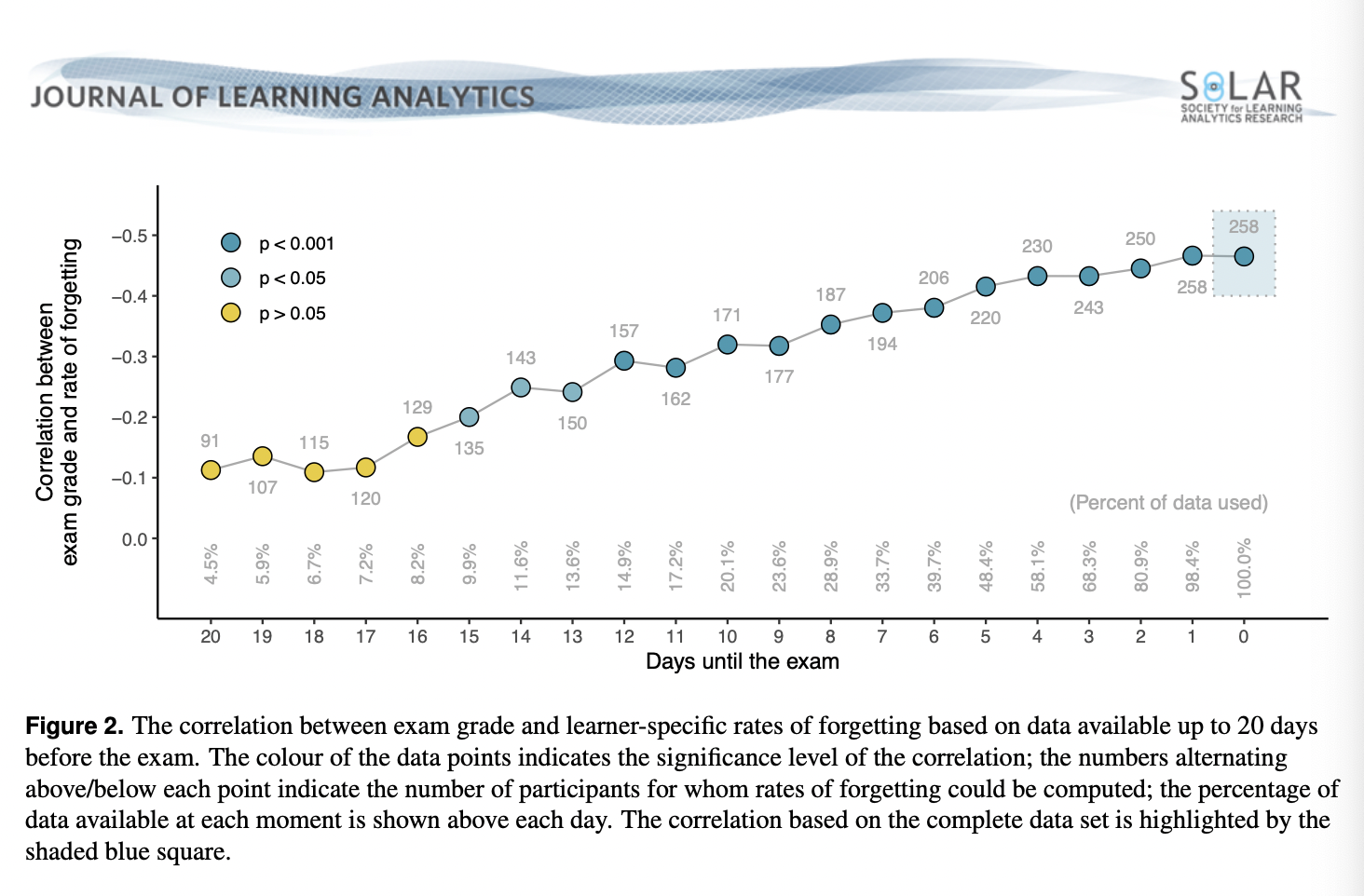
In practice, a possible relationship between someone’s rate of forgetting and eventual exam performance would be most useful if it could be detected ahead of time rather than on the day of the exam—when it is too late to potentially help struggling students, for example
This pattern could be driven by additional learners that start at the last minute and demonstrate poor learning performance and poor grades
Predicting Performance on Individual Exam Questions
The results reported so far confirm that the expected patterns emerged in the aggregate: a learner’s average rate of forgetting was strongly related to their average performance on the exam
A step-wise backward elimination procedure was used to find the best model: starting with the full model, the term with the lowest absolute z-value was removed until the simpler model was no longer preferred on the basis of BIC and AIC (Gelman & Hill, 2006).
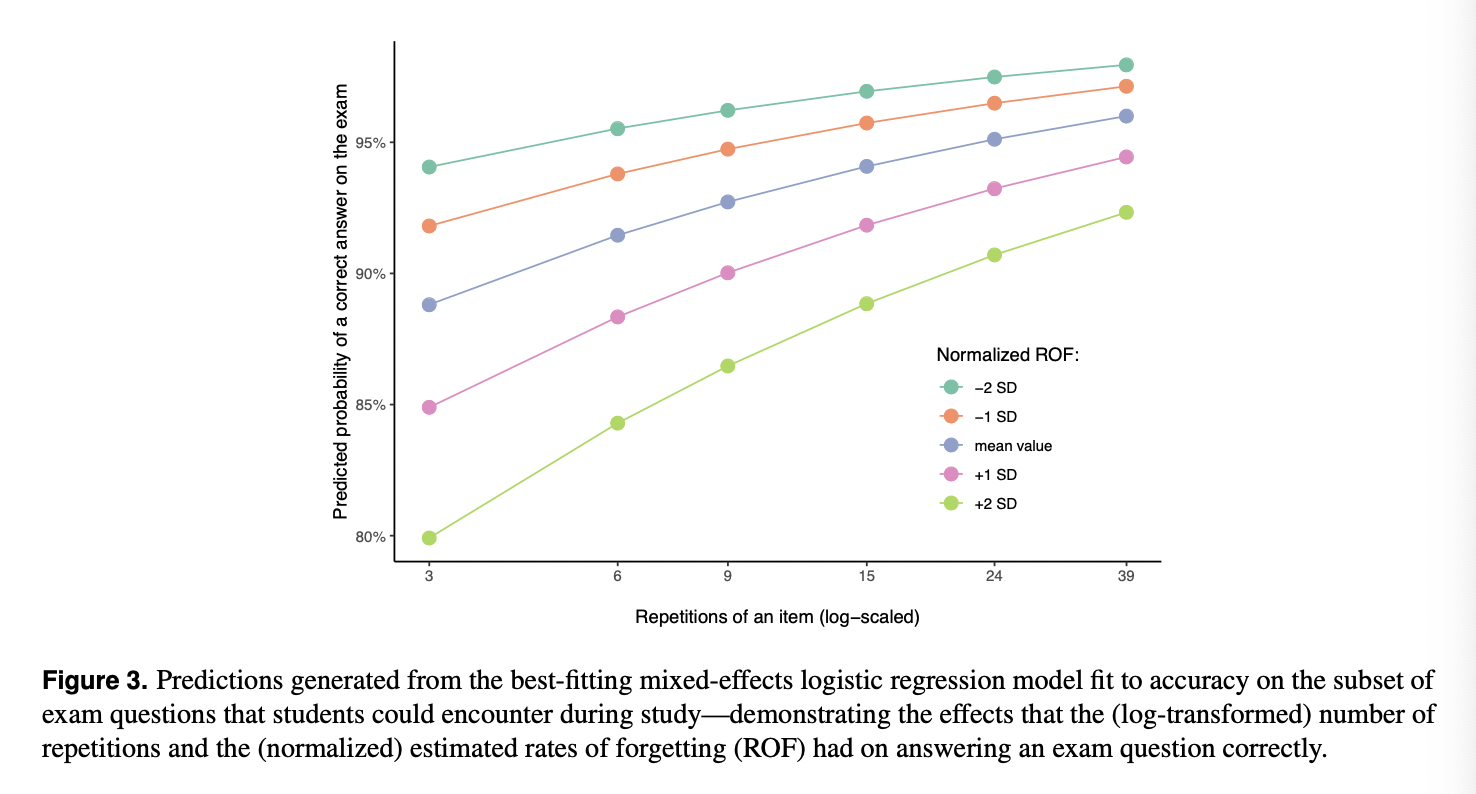
Additionally, the estimated rate of forgetting modulated the effect such that learner– item combinations with very low rates of forgetting have a higher chance of yielding a correct answer.
The differences in rates of forgetting are especially pronounced at a low number of repetitions due to the non-linear mapping between the predictors and the predicted probability introduced by the logit function
Predicting Performance on the Exam
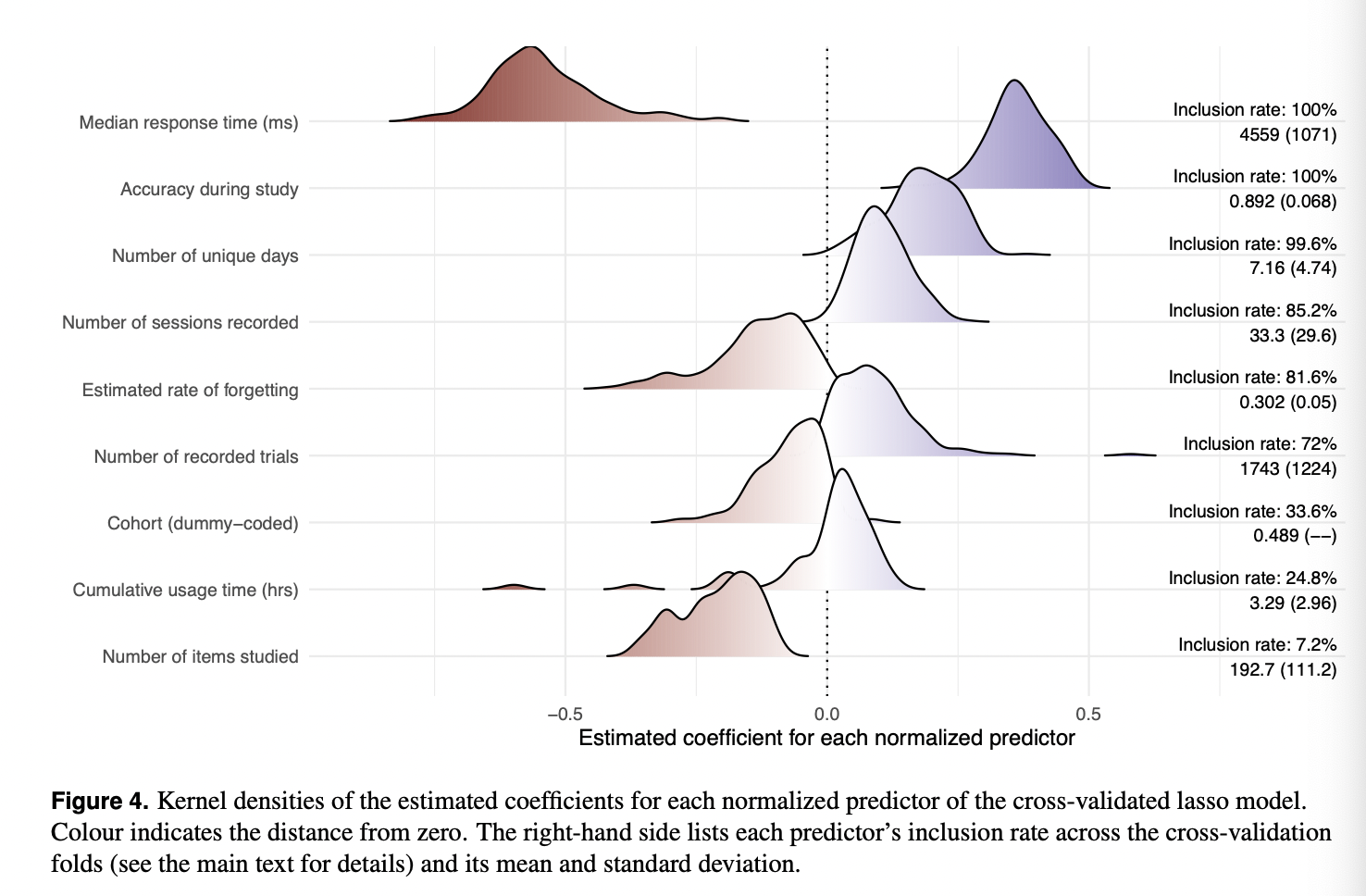
We used lasso regression (Tibshirani, 1996) to predict grades using nine predictors: a student’s accuracy during study, their cohort, their cumulative usage time, the number of days on which they used the system, the number of items they studied, the number of sessions they recorded, the number of trials they completed, their estimated rate of forgetting, and their median response time
The advantage of lasso regression is that the Shrinkage term handles multicollinearity between the predictors by shrinking their coefficients
The Shrinkage is achieved by imposing a cost function on the magnitude of the
coefficients themselves: the best fit is achieved by the model that minimizes the OLS with the smallest coefficients. In fact, coefficients are shrunk entirely if they do not explain sufficient variance to justify inclusion in the model. In lasso regression, predictors must be normalized to ensure that the Shrinkage term affects all predictors equally. A convenient consequence of normalized predictors is that their post-Shrinkage
coefficients directly indicate their importance: since all predictors are on the same scale, the most important predictor retains the largest (absolute) coefficient.
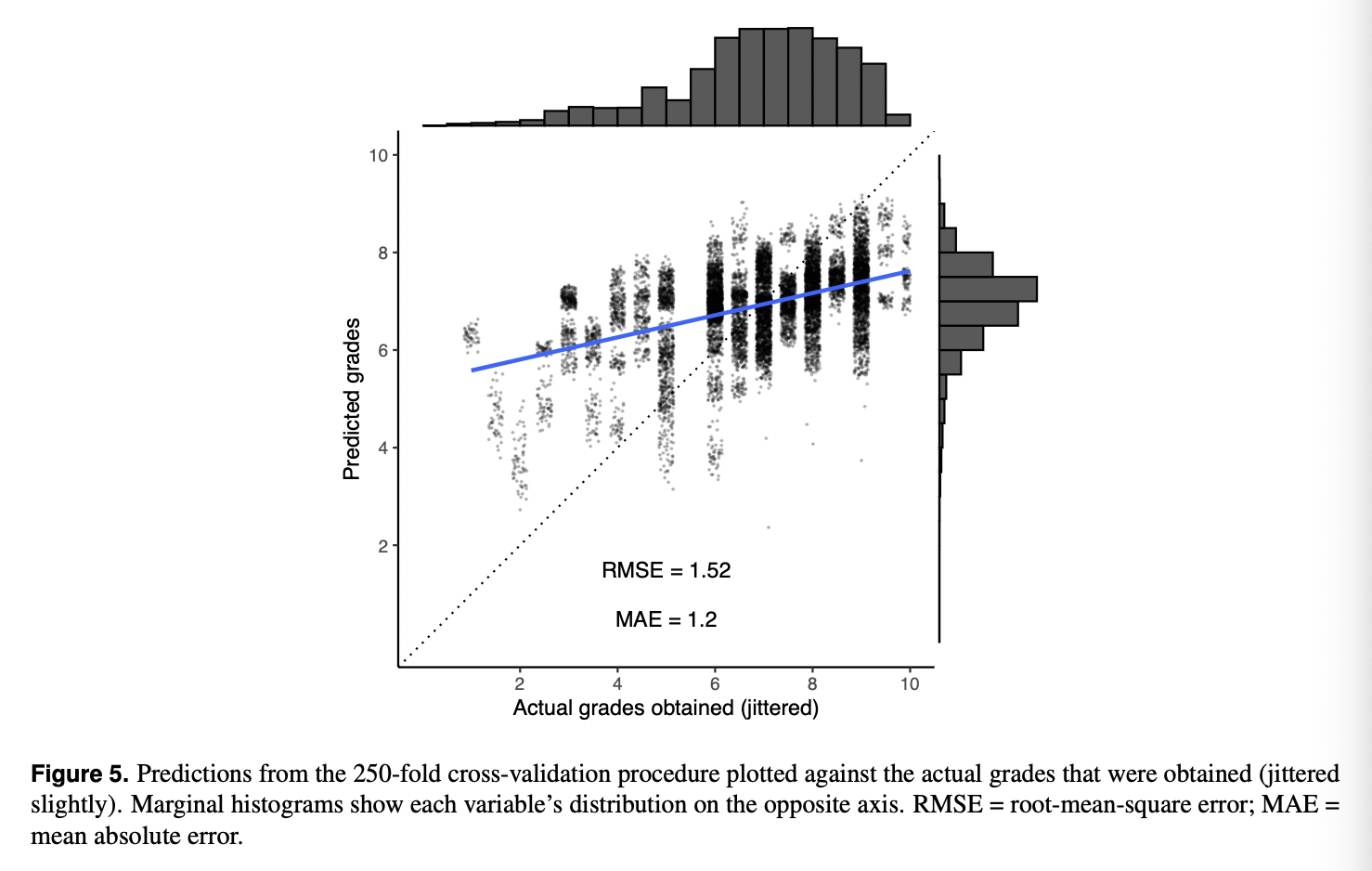
250-fold cross-validation procedure
Comparing Self-Reported and Recorded Study Times
This means that students who used SlimStampen more did not necessarily self- report studying more overall. Thus, the positive association between more SlimStampen usage and higher grades was unlikely to be a consequence of higher motivation alone.
This suggests, unsurprisingly, that general studiousness led to higher exam performance
More interestingly, time spent studying with SlimStampen was time well spent, as the expected gain in grades associated with additional hours of study was 0.11 points, compared to only 0.03 points gained by an hour of unspecified study time.
Discussion
Students’ rates of forgetting, estimated by the system during use, were correlated with exam performance up to two weeks before the exam (Figure 2), even though < 5% of the data were available at that point
Furthermore, rate-of-forgetting estimates for individual facts were predictive of learners’ performance on the associated exam questions, along with the number of times these facts were repeated during study
One limitation of the sample was that we did not know what other study methods students may have used alongside the system. It is possible that the spike in activity in the days preceding the exam was caused by students verifying that they had retained the knowledge obtained through other study activities
Implications
controlling within-session study decisions through the adaptive fact-learning system, leaving other study decisions—when to study, which chapter to study, how long to study, and whether to study with open response or multiple-choice questions—to the learner
students still made sub-optimal decisions about when to repeat a lesson that they had studied previously.
Alternatively, the system could suggest the lesson that would yield the largest learning gain at the moment a student decides to start a session