Self Supervised Survey
Abstract
- Large-scale labeled data are generally required to train deep neural networks in order to obtain better performance in visual feature learning from images or videos for computer vision applications
- as a subset of unsupervised learning methods, self-supervised learning methods are proposed to learn general image and video features from large-scale unlabeled data without using any human-annotated labels
Motivation
-
The performance of deep convolutional neural networks (ConvNets) greatly depends on their capability and the amount of training data.
-
collection and annotation of large-scale datasets are time-consuming and expensive
-
Compared to image datasets, collection and annotation of video datasets are more expensive due to the temporal dimension
-
To avoid time-consuming and expensive data annotations, many self-supervised methods were proposed to learn visual features from large-scale unlabeled images or videos without using any human annotations
-
During the self-supervised training phase, a predefined pretext task is designed for ConvNets to solve, and the pseudo labels for the pretext task are automatically generated based on some attributes of data
-
Then the ConvNet is trained to learn object functions of the pretext task
-
After the self-supervised training finished, the learned visual features can be further transferred to downstream tasks (especially when only relatively small data available) as pretrained models to improve performance and overcome over- fitting.
-
shallow layers capture general low-level features like edges, corners, and textures while deeper layers capture task related high-level features
-
[Pseudo Label](Pseudo Label.md)
-
[Pretext Task](Pretext Task.md)
-
[Downstream Task](Downstream Task.md)
-
[Weakly-supervised Learning](Weakly-supervised Learning.md)
FORMULATION OF DIFFERENT LEARNING SCHEMAS
-
[Supervised Learning Formulation](Supervised Learning Formulation.md)
-
[Semi-Supervised Learning Formulation](Semi-Supervised Learning Formulation.md)
-
[Weakly Supervised Learning Formulation](Weakly Supervised Learning Formulation.md)
-
[Self-supervised Learning](Self-supervised Learning.md)
NN
- [Spatiotemporal Convolutional Neural Network](Spatiotemporal Convolutional Neural Network.md)
Pretext Tasks
- [Pretext Tasks](Pretext Tasks.md)
Datasets
-
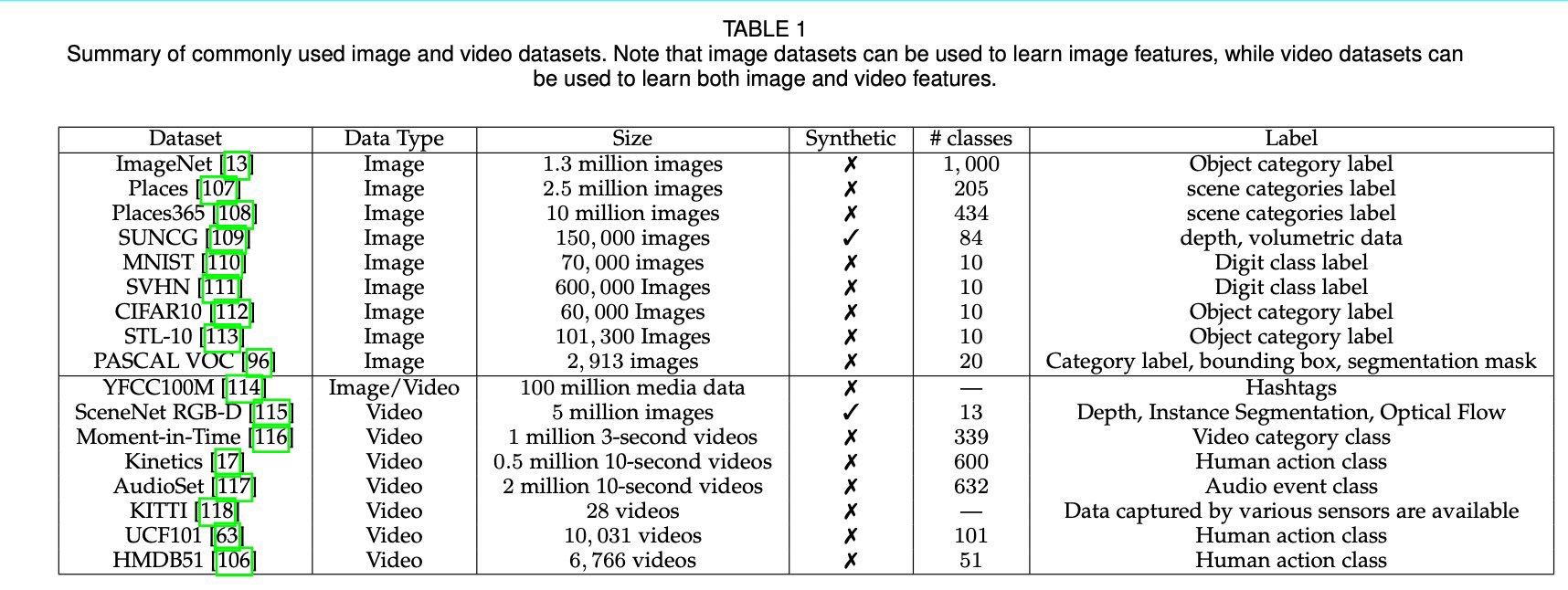
-
[SceneNet RGB-D](SceneNet RGB-D.md)
-
[Moment in Time](Moment in Time.md)
Other Tasks
-
[Image Generation with Inpainting](Image Generation with Inpainting.md)
-
[Image Generation with Super Resolution](Image Generation with Super Resolution.md)
-
[Image Generation with Colorization](Image Generation with Colorization.md)
-
[Learning with Context Similarity](Learning with Context Similarity.md)
-
[Learning with Spatial Context Structure](Learning with Spatial Context Structure.md)
-
[Learning with Labels Generated by Game Engines](Learning with Labels Generated by Game Engines.md)
-
[Learning with Labels Generated by Hard-code Programs](Learning with Labels Generated by Hard-code Programs.md)
-
[Learning from Video Colorization](Learning from Video Colorization.md)
-
[Learning from Video Prediction](Learning from Video Prediction.md)
-
[Learning from RGB-Flow Correspondence](Learning from RGB-Flow Correspondence.md)
-
[Learning from Visual-Audio Correspondence](Learning from Visual-Audio Correspondence.md)