Randaugment: Practical automated data augmentation with a reduced search space
Ekin D. Cubuk ∗, Barret Zoph∗, Jonathon Shlens, Quoc V. Le
ChatGPT Summary
Large-scale adoption of data augmentation methods is hindered by the need for a separate and expensive search phase.
Commonly, a smaller proxy task is used to overcome the expense of the search phase, but it is not clear if the optimized hyperparameters found on the proxy task are also optimal for the actual task.
The process of designing automated augmentation strategies is being rethought.
It is proposed to only search for a single distortion magnitude that jointly controls all operations, which reduces computational expense and eliminates the need for a separate proxy task.
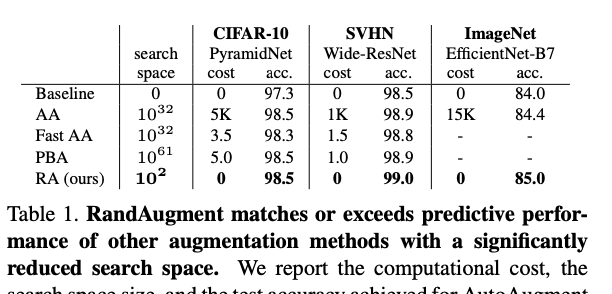
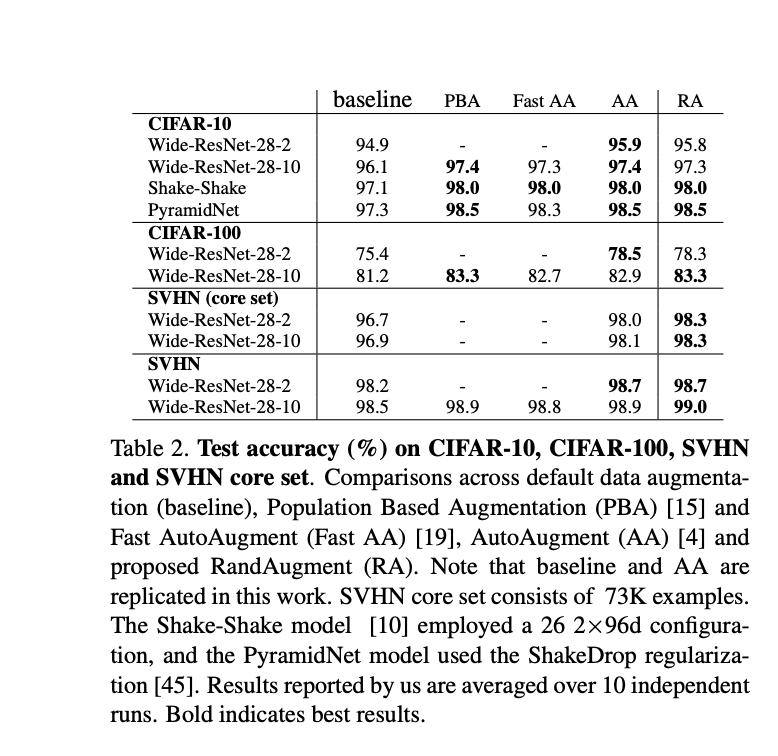
The proposed method was tested on various datasets including [CIFAR]-10, [CIFAR](CIFAR]-10, [CIFAR.md) 100, SVHN, ImageNet, and COCO, and showed improvement in performance without the use of a proxy task.
The proposed method, RandAugment, uses a parameter-free procedure of always selecting a transformation with uniform probability from a set of K=14 available transformations, and a single distortion magnitude that jointly controls all operations.
RandAugment is able to achieve comparable or better performance compared to other automated augmentation methods, such as AutoAugment, without the need for a separate proxy task.
The results suggest that the optimal data augmentation policies may depend on the specific model and dataset size, and a small proxy task may not provide the best indicator of performance on a larger task.
Abstract
An obstacle to a large-scale adoption of these methods is that they require a separate and expensive search phase
A common way to overcome the expense of the search phase was to use a smaller proxy task.
However, it was not clear if the optimized hyperparameters found on the proxy task are also optimal for the actual task.
rethink the process of designing automated augmentation strategies
it is sufficient to only search for a single distortion magnitude that jointly controls all operations
propose a simplified search space that vastly reduces the computational expense of automated augmentation, and permits the removal of a separate proxy task.
A central premise of learned data augmentation is to construct a small, proxy task that may be reflective of a larger task
Although this assumption is sufficient for identifying learned augmentation policies to improve performance, it is unclear if this assumption is overly stringent and may lead to sub-optimal data augmentation policies.
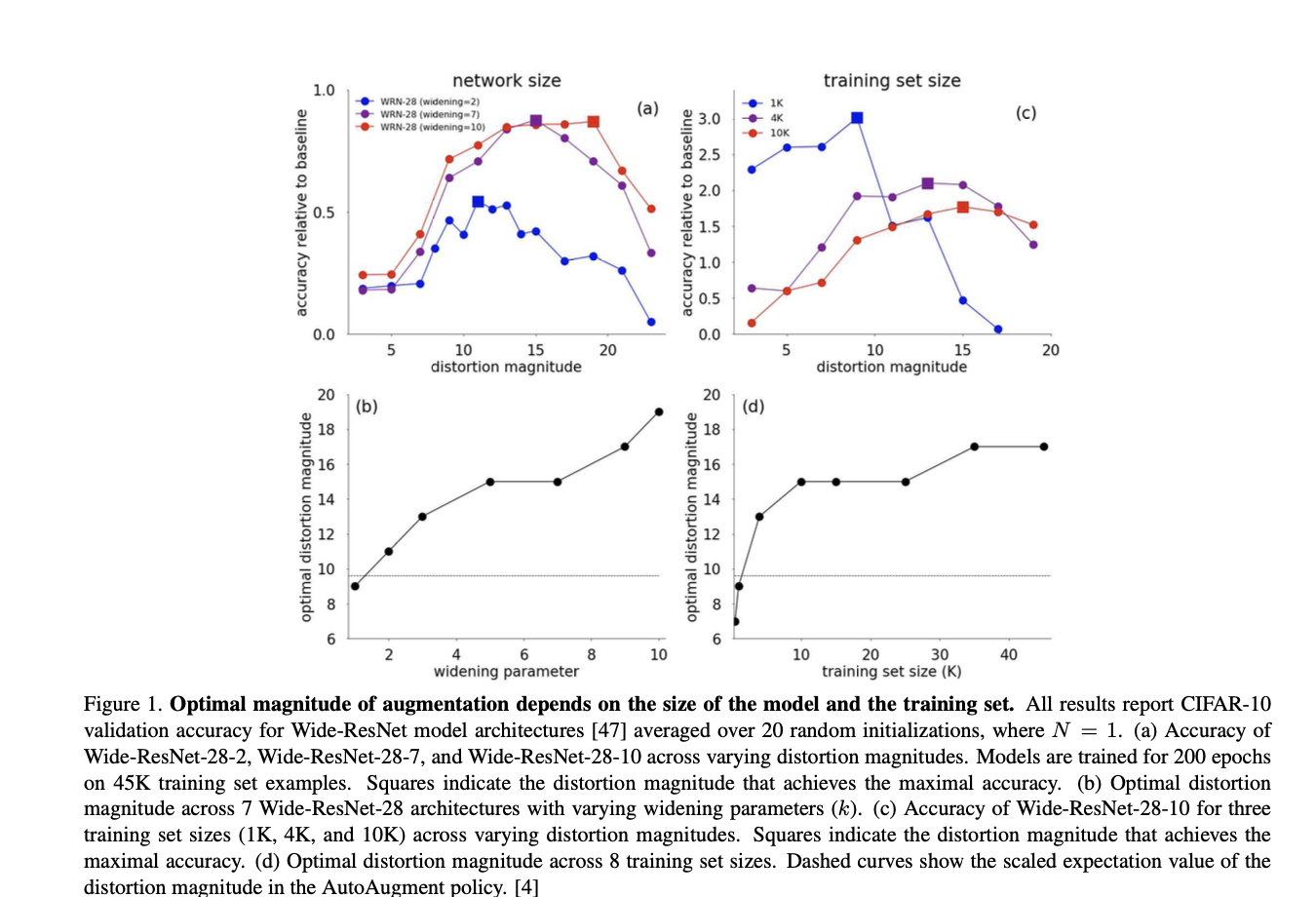
two separate dimensions that are commonly restricted to achieve a small proxy task: model size and dataset size
First, we train a family of Wide-ResNet architectures, where the model size may be systematically altered through the widening parameter governing the number of convolutional filters
For each of these networks, we train the model on CIFAR-10 and measure the final accuracy compared to a baseline model trained with default data augmentations (i.e. horizontal flips and pad-and-crop)
The Wide-ResNet models are trained with the additional K=14 data augmentations (see Section 3) over a range of global distortion magnitudes M parameterized on a uniform linear scale ranging from [0, 30]
Namely, larger networks demand larger data distortions for Regularization
Conversely, a policy learned on a proxy task (such as AutoAugment) provides a fixed distortion magnitude (Figure 1b, dashed line) for all architectures that is clearly sub-optimal.
A second dimension for constructing a small proxy task is to train the proxy on a small subset of the training data
We first observe that models trained on smaller training sets may gain more improvement from data augmentation
see that the optimal distortion magnitude is larger for models that are trained on larger datasets.
optimal distortion magnitude increases monotonically with training set size
One hypothesis for this counter-intuitive behavior is that aggressive data augmentation leads to a low signal-to-noise ratio in small datasets
learned augmentation may learn an augmentation strength more tailored to the proxy task instead of the larger task of interest.
The dependence of augmentation strength on the dataset and model size indicate that a small proxy task may provide a sub-optimal indicator of performance on a larger task.
Automated Data Augmentation without a Proxy Task
The reason we wish to remove the search phase is because a separate search phase significantly complicates training and is computationally expensive.
In order to remove a separate search phase, we aspire to fold the parameters for the data augmentation strategy into the hyper-parameters for training a model.
Indeed, previous work enumerated a policy in terms of choosing which transformations to apply out of K=14 available transformations, and probabilities for applying each transformation:
age diversity, we replace the learned policies and probabilities for applying each
transformation with a parameter-free procedure of always selecting a transformation with uniform probability K1
Given N transformations for a training image, RandAugment may thus express KN potential policies.
magnitude of the each augmentation distortion.
Briefly, each transformation resides on an integer scale from 0 to 10 where a value of 10 indicates the maximum scale for a given transformation
A data augmentation policy consists of identifying an integer for each augmentation.
and postulate that a single global distortion M may suffice for parameterizing all transformations
We experimented with four methods for the schedule of M during training: constant magnitude, random magnitude, a linearly increasing magnitude, and a random magnitude with increasing upper bound
The resulting algorithm contains two parameters N and M
Both parameters are human-interpretable such that larger values of N and M increase Regularization strength
In order to reduce the parameter space but still maintain imInvestigating the dependence on the included transformations
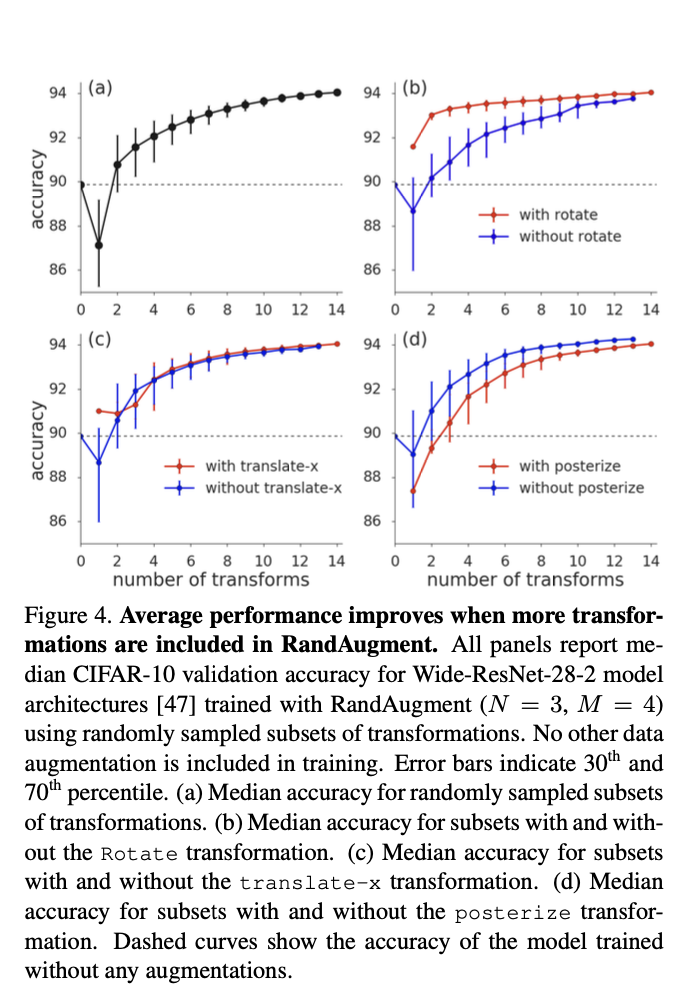
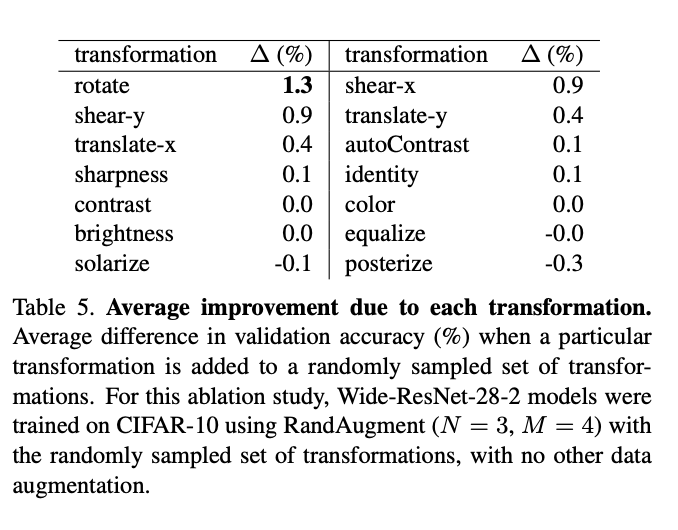
RandAugment is largely insensitive to the selection of transformations for different datasets.
We see that while [geometric transformations](geometric transformations.md) individually make the most difference, some of the color transformations lead to a degradation of validation accuracy on average
Surprisingly, rotate can significantly improve performance and lower variation even when included in small subsets of RandAugment transformations, while posterize seems to hurt all subsets of all sizes.
Learning the Probabilities for Selecting Image Transformations
For K=14 image transformations and N =2 operations, αij constitutes 28 parameters. We initialize all weights such that each transformation is equal probability (i.e. RandAugment), and update these parameters based on how well a model classifies a held out set of validation images distorted by αij.
This approach was inspired by density matching [19], but instead uses a differentiable approach in lieu of Bayesian optimization.
We label this method as a 1st-order density matching approximation.
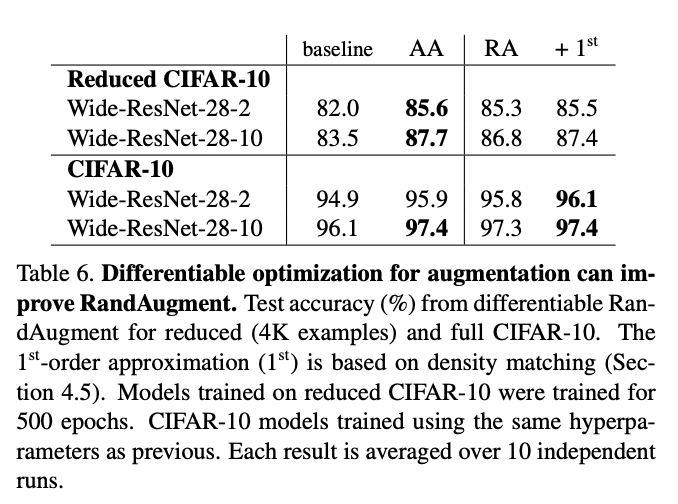
The 1st -order method improves accuracy by more than 3.0% for both models on reduced CIFAR-10 compared to the baseline of flips and pad-and-crop
Although the density matching approach is promising, this method can be expensive as one must apply all K transformations N times to each image independently.
Hence, because the computational demand of KN transformations is prohibitive for large images, we reserve this for future exploration.
learning the probabilities through density matching may improve the performance on small-scale tasks and reserve explorations to larger-scale tasks for the future.
RandAugment selects all image transformations with equal probability
This opens up the question of whether learning K probabilities may improve performance further.
Most of the image transformations (except posterize, equalize, and autoContrast) are differentiable, which permits backpropagation to learn the K probabilities
Discussion
not tailoring the number of distortions and the distortion magnitude to the dataset size nor the model size leads to sub-optimal performance
In previous work, scaling learned data augmentation to larger dataset and models have been a notable obstacle. For example, [AutoAugment] and Fast [AutoAugment](AutoAugment] and Fast [AutoAugment.md) could only be optimized for small models on reduced subsets of data
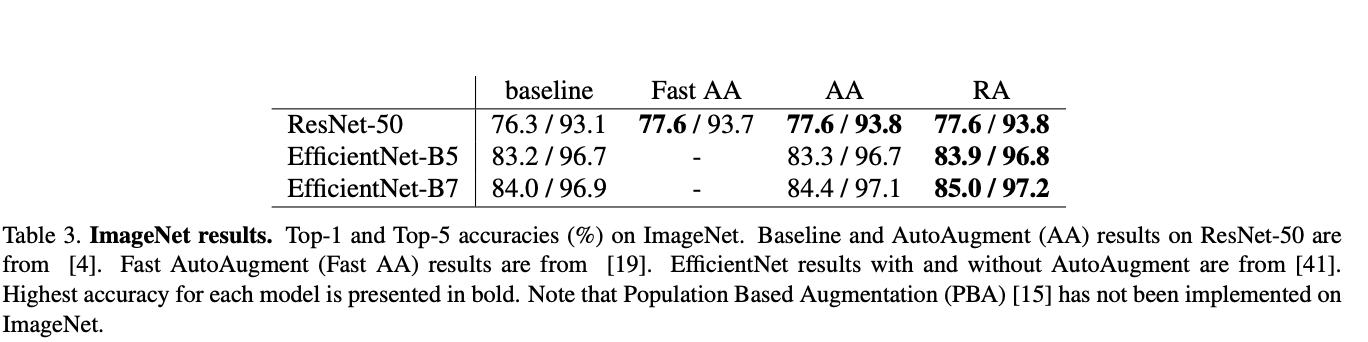
The proposed method scales quite well to datasets such as ImageNet and COCO while incurring minimal computational cost (e.g. 2 hyper-parameters), but notable predictive performance gains.