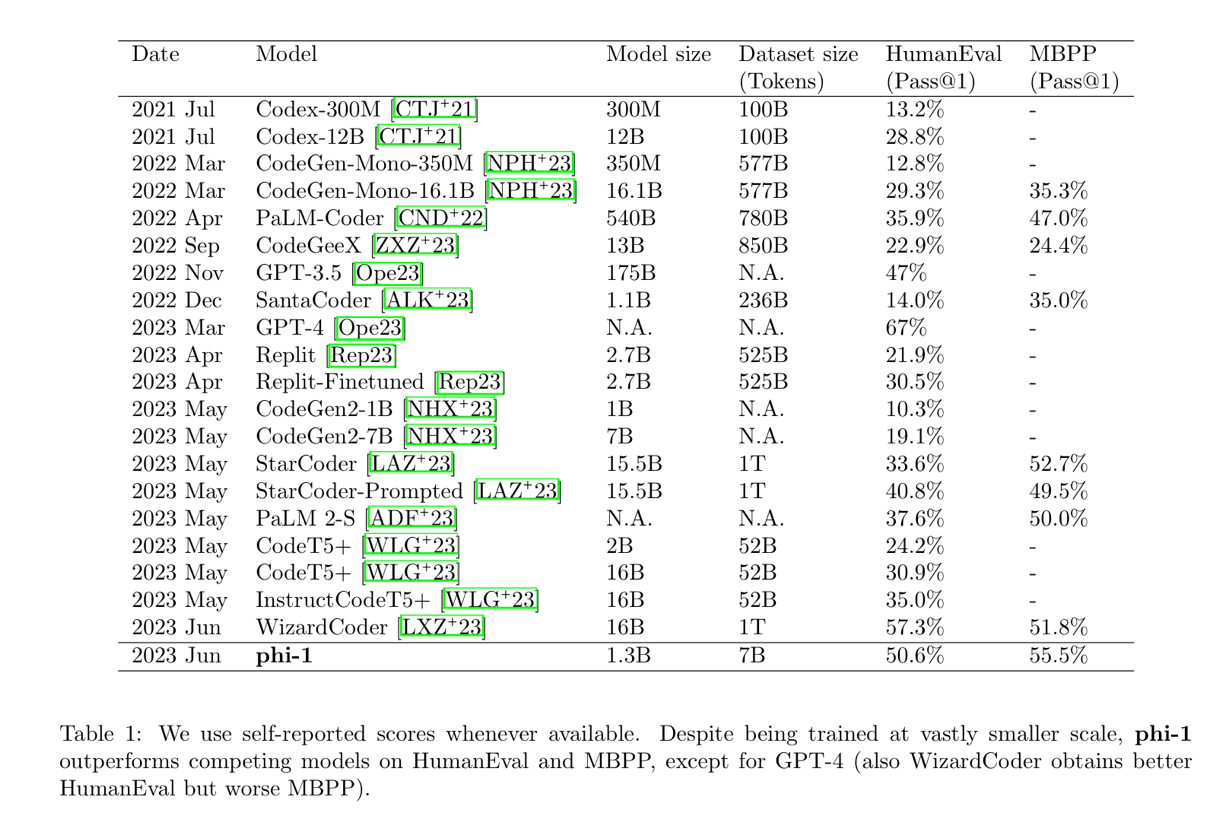
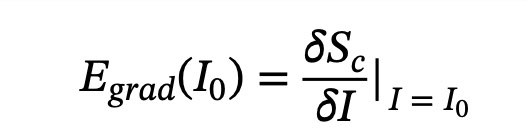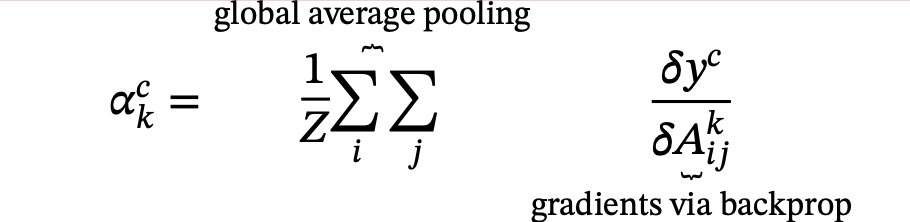Summary : Summary : Uses a transformer network to prediction a “prompt” that says how degraded an image is. And based on that, decides what module to use.
Deep learning-based methods have significantly improved image restoration performance, however, they have limited generalization ability to different degradation types and levels
requires training individual models for each specific degradation and knowing the input degradation type to apply the relevant model.
prompt-based learning approach, PromptIR, for All-In-One image restoration that can effectively restore images from various types and levels of degradation
uses prompts to encode degradation-specific information
generic and efficient plugin module with few lightweight prompts that can be used to restore images of various types and levels of degradation with no prior information on the corruptions present in the image
AirNet
addresses the all-in-one restoration task by employing the contrastive learning paradigm.
involves training an extra encoder to differentiate various types of image degradations
Although AirNet [29] yields state-of-the-art results, it struggles to model fully disentangled representations of different corruption types
Furthermore, the usage of an additional encoder for contrastive learning leads to a higher training burden due to the two-stage training approach.
Method
aim to learn a single model M to restore an image I from a degraded image I, that has been degraded using a degradation D, while having no prior information about D.
While the model is initially “blind” to the nature of degradation, its performance in recovering a clean image can be enhanced by providing implicit contextual information about the type of degradation
From a given degraded input image I ∈ RH ×W ×3
first extracts low-level features F0 ∈ RH×W×C by applying a convolution operation; where H × W is the spatial resolution and C denotes the channels.
eature embeddings F0 undergo a 4-level hierarchical encoder-decoder, transforming into deep features Fr ∈ RH ×W ×2C
Each level of the encoder-decoder employs several Transformer blocks, with the number of blocks gradually increasing from the top level to the bottom level to maintain computational efficiency.
Starting from the high-resolution input, the goal of the encoder is to progressively reduce the spatial resolution while .
From the low-resolution latent features Fl, the aim of the decoder is to gradually recover the highresolution clean output
ncorporate prompt block
Prompt blocks are adapter modules that sequentially connect every two levels of the decoder.
Prompt Block
Prompt Generation Module
Prompt components Pc form a set of learnable parameters that interact with the incoming features to embed degradation information
features-prompt interaction is to directly use the learned prompts to calibrate the features.
dynamically predicts attention-based weights from the input features and apply them to prompt components to yield input-conditioned prompts P
shared space to facilitate correlated knowledge sharing among prompt components.
To generate prompt-weights from the input features Fl
first applies global average pooling (GAP) across spatial dimension to generate feature vector v 2 RCˆ
pass v through a channeldownscaling convolution layer to obtain a compact feature vector, followed by the softmax operation, thus yielding prompt-weights w 2 RN
use these weights to make adjustments in prompt components, followed by a 3 x 3 convolution layer
Since at inference time, it is necessary for the restoration network to be able to handle images of different resolutions, we cannot use the prompt components Pc with a fixed size.
bilinear upsampling operation to upscale the prompt components
Prompt Interaction Module
enable interaction between the input features Fl and prompts P for a guided restoration.
In PIM, we concatenate the generated prompts with the input features along the channel dimension.
pass the concatenated representations through a Transformer block that exploits degradation information encoded in the prompts and transforms the input features.
The Transformer block is composed of two sequentially connected sub-modules: Multi-Dconv head transposed attention (MDTA), and Gated-Dconv feedforward network (GDFN). MDTA applies self-attention operation across channels rather than the spatial dimension and has linear complexity.
The goal of GDFN is to transform features in a controlled manner, i.e., suppressing the less informative features and allowing only useful ones to propagate through the network
Implementation Details
end-to-end trainable and requires no pretraining of any individual component
4-level encoder-decoder, with varying numbers of Transformer blocks at each level, specifically [4, 6, 6, 8] from level-1 to level-4.
one prompt block between every two consecutive decoder levels, totaling 3 prompt blocks in the overall PromptIR network
The total number of prompt components are 5
The model is trained with a batch size of 32 in the all-in-one setting, and with a batch of 8 in the single-task setting
The network is optimized with an L1 loss, and we use Adam optimizer (1 = 0.9, 2 = 0.999) with learning rate 2e 4 for 200 epochs.