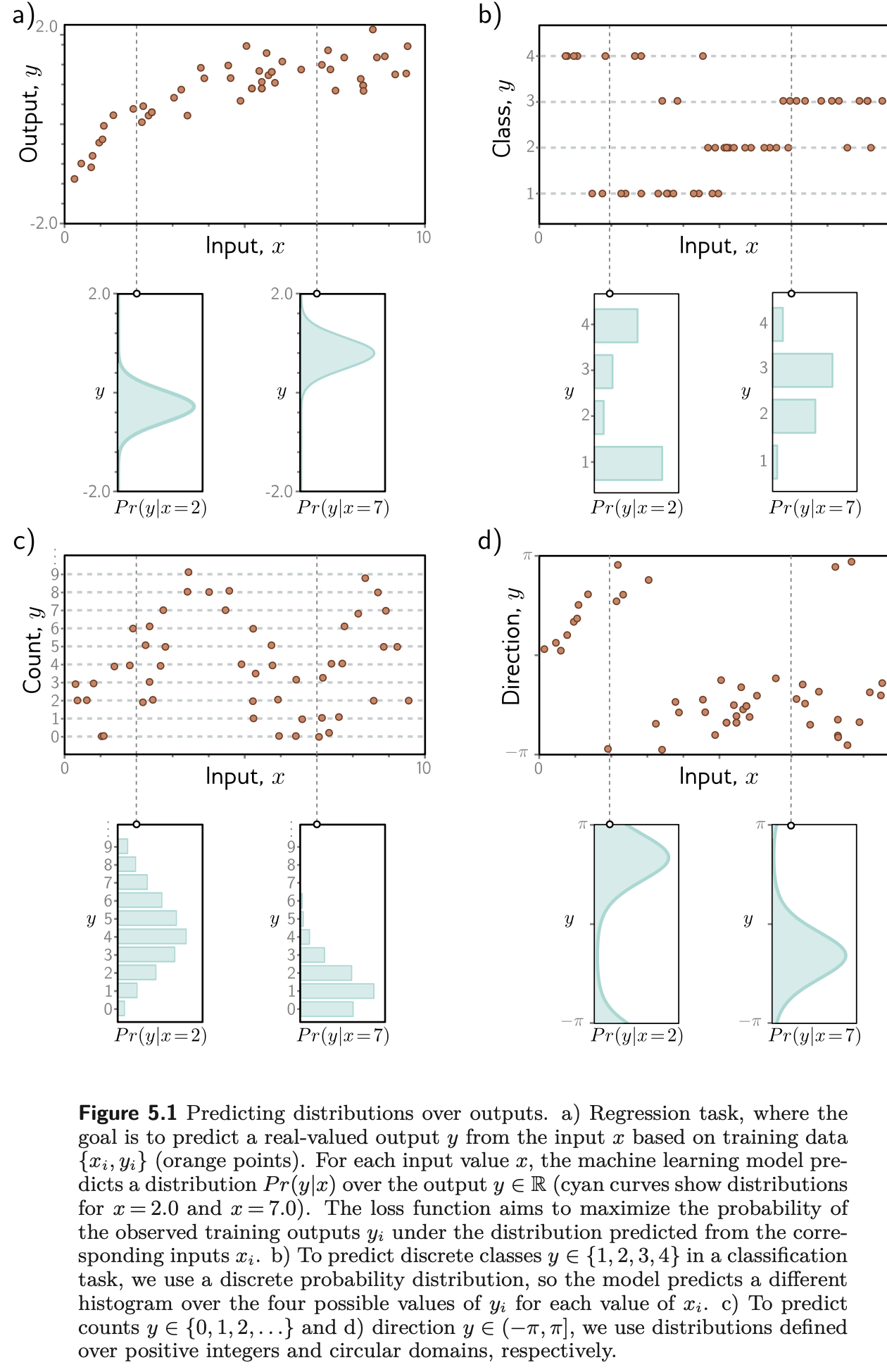
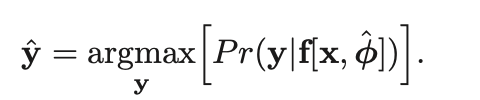Consider a model f[x,ϕ] that computes an output from input x.
Consider the model computes a conditional probability distribution Pr(Y∣x) , Y is output
This encourages each output yi to have high probability under Pr(yi∣xi) computed from input xi
Computing a distribution over inputs
Choose a parametric distribution Pr(y∣θ) defined on output domain y.
use the network to compute one or more of the parameters θ of this distribution
For example, suppose the prediction domain is the set of real numbers, so y ∈ R. Here, we might choose the univariate normal distribution, which is defined on R. This distribution is defined by the mean μ and variance σ2, so θ = {μ,σ^2}. The machine learning model might predict the mean μ, and the variance σ^2 could be treated as an unknown constant.