Lost in the Middle How Language Models Use Long Contexts
Summary
When we feed LLMs with a long context, they tend to overlook the documents placed in the middle. So, contrary to what one might think, placing the least similar documents at the bottom isn’t the best strategy. So, we should put the least similar ones in the middle, not at the bottom.
Findings
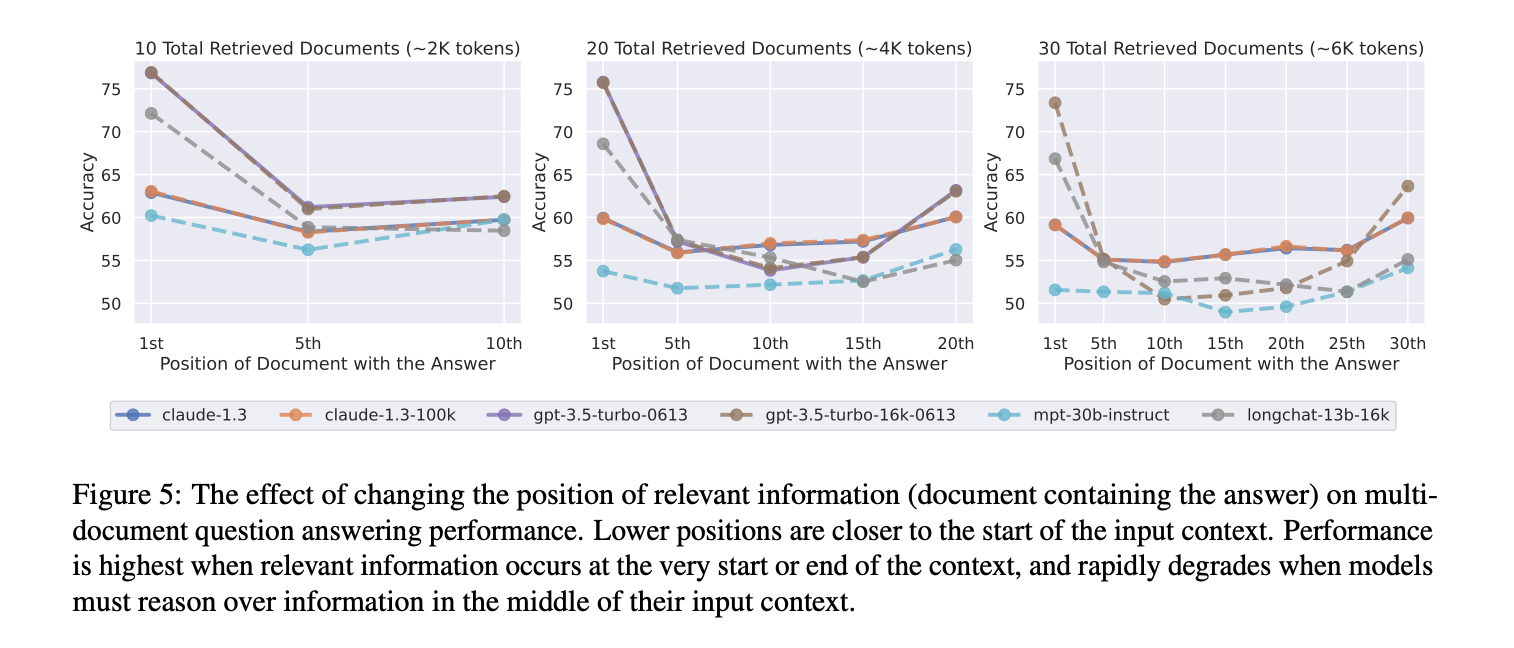
- performance can degrade significantly when changing the position of relevant information, indicating that current language models do not robustly make use of information in long input contexts.
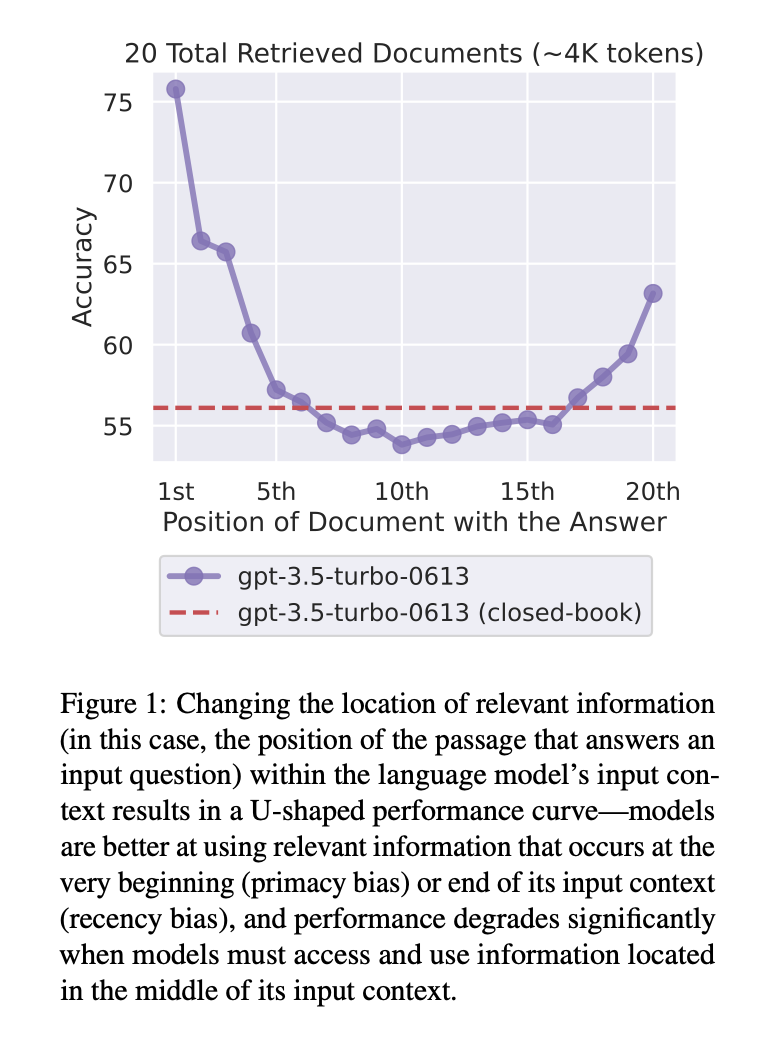
- performance is often highest when relevant information occurs at the beginning or end of the input context, and significantly degrades when models must access relevant information in the middle of long contexts, even for explicitly long-context models
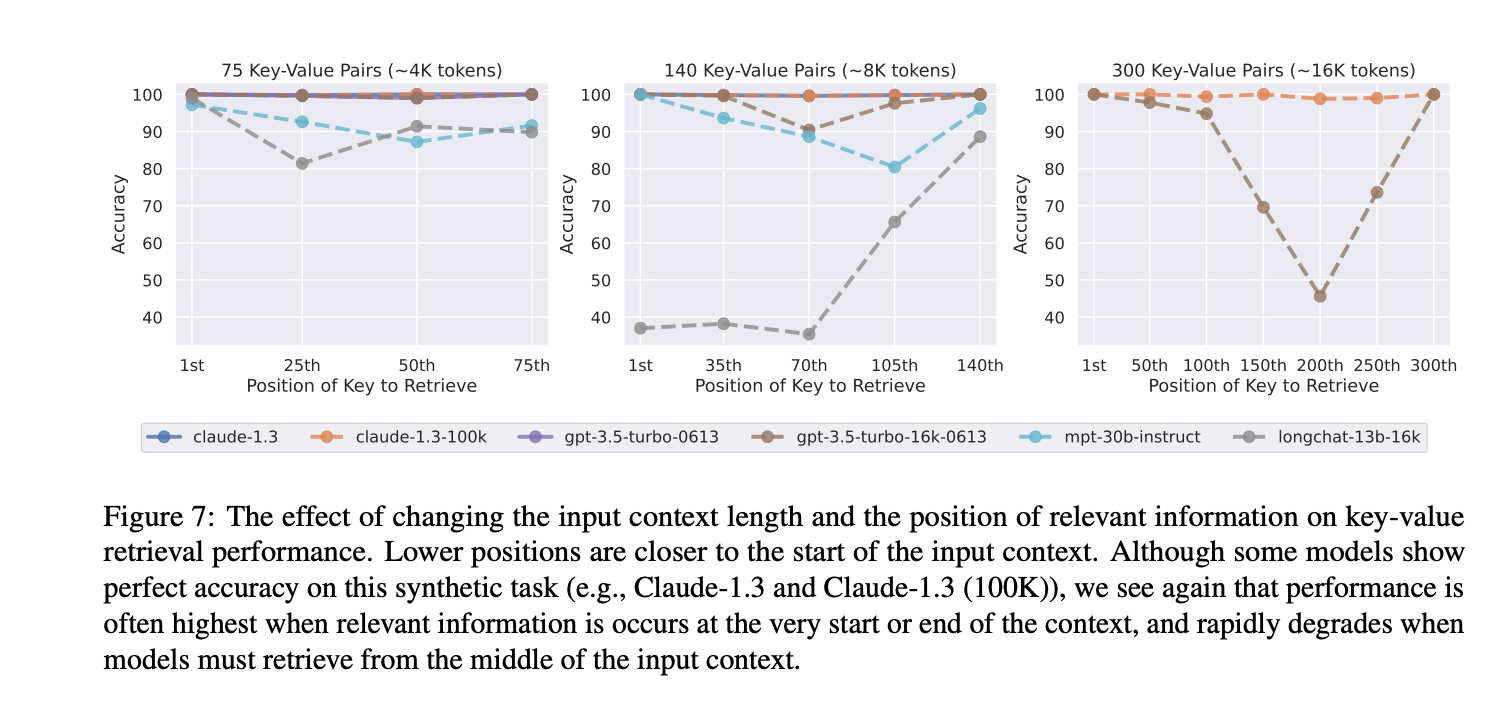
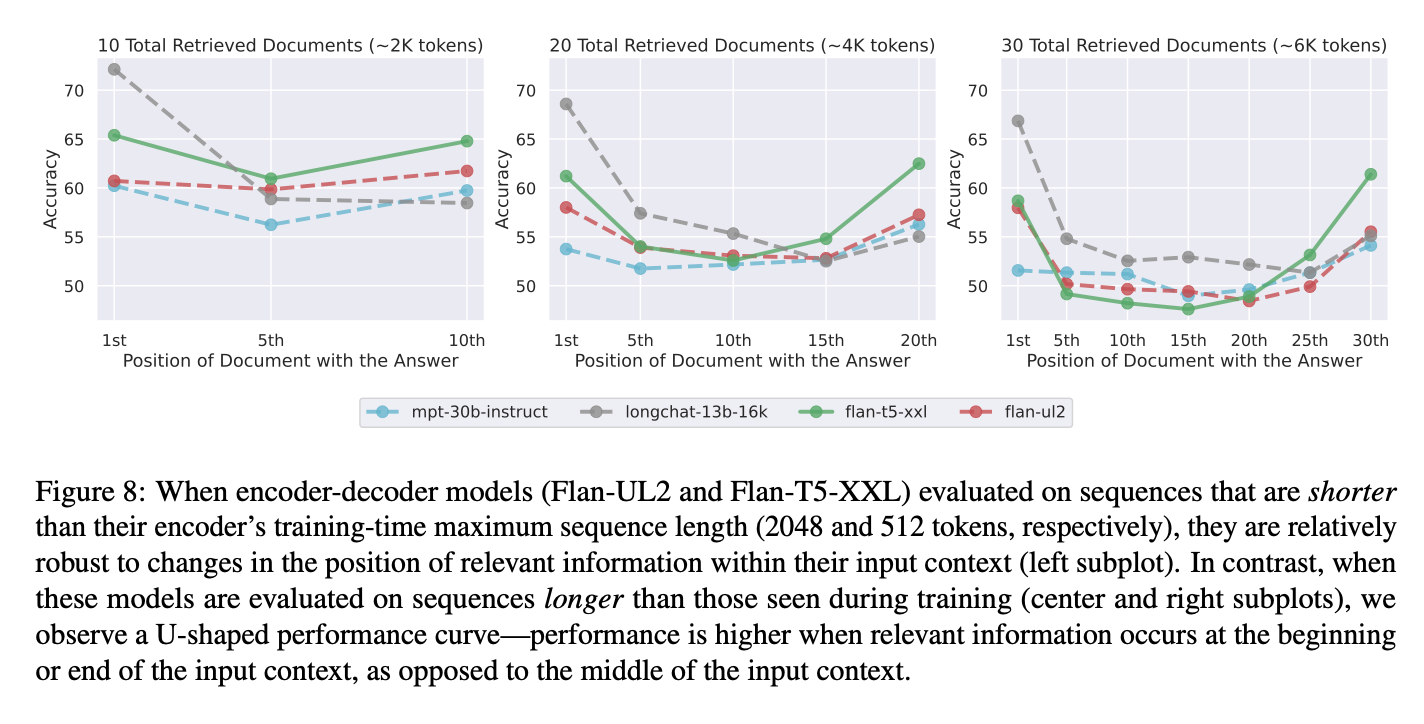
- Encoder-decoder models are relatively robust to changes in the position of relevant information within their input context, but only when evaluated on sequences within its trainingtime sequence length. When evaluated on sequences longer than those seen during training, we observe a U-shaped performance curve
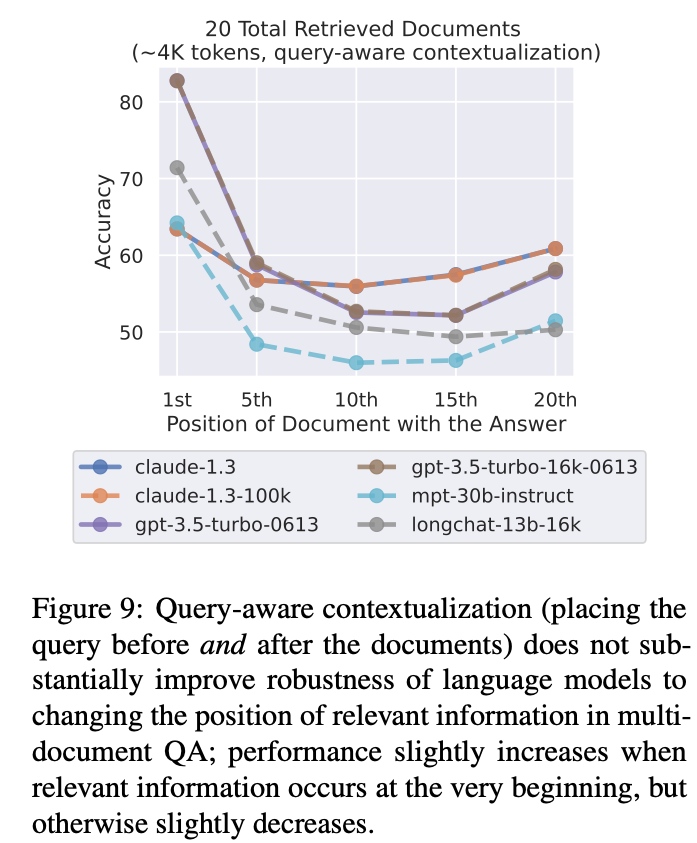
- Query-aware contextualization (placing the query before and after the documents or keyvalue pairs) enables near-perfect performance on the synthetic key-value task, but minimally changes trends in multi-document QA
- Even base language models (i.e., without instruction fine-tuning) show a U-shaped performance curve as we vary the position of relevant information in the input context.
- model performance saturates long before retriever recall saturates, indicating that current models fail to effectively use additional retrieved documents---using 50 documents instead of 20 retrieved documents only marginally improves performance (∼1.5% for GPT-3.5-Turbo and ∼1% for claude-1.3).
Results
- Our experimental setup is similar to the needlein-a-haystack experiments of Ivgi et al. (2023), who compare question answering performance when the relevant paragraph is placed (i) at the beginning of the input or (ii) a random position within the input. They find that encoder-decoder models have significantly higher performance when relevant information is placed at the start of the input context. In contrast, we study finer-grained changes in the position of relevant information.