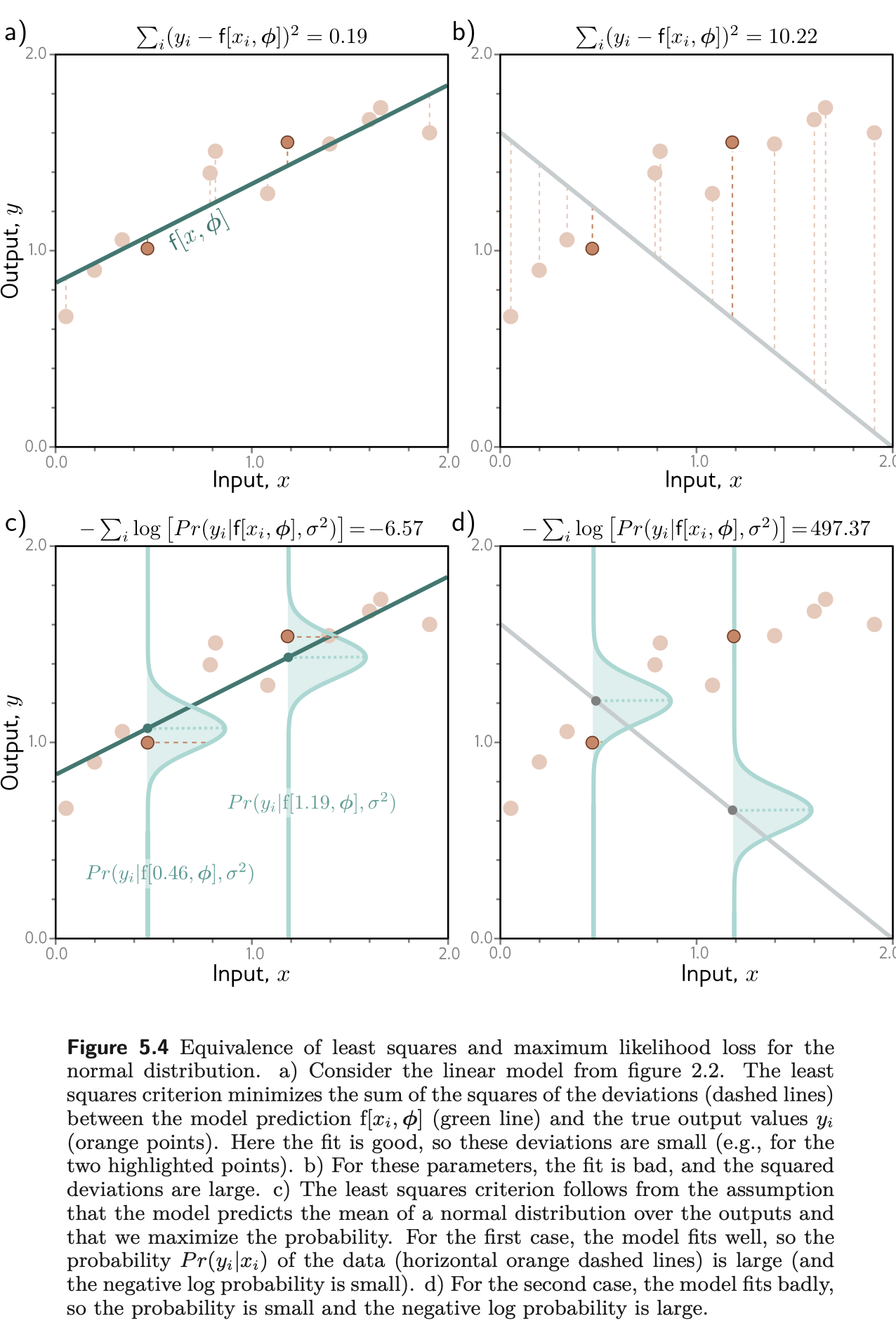
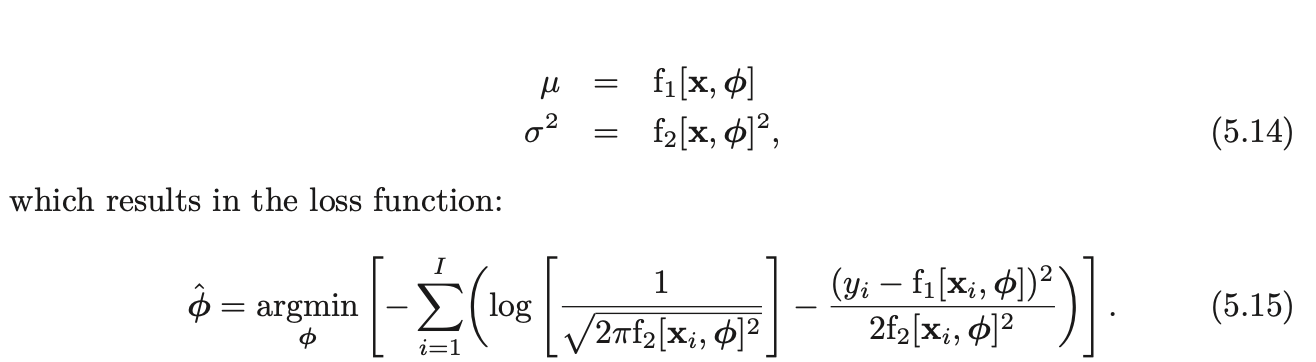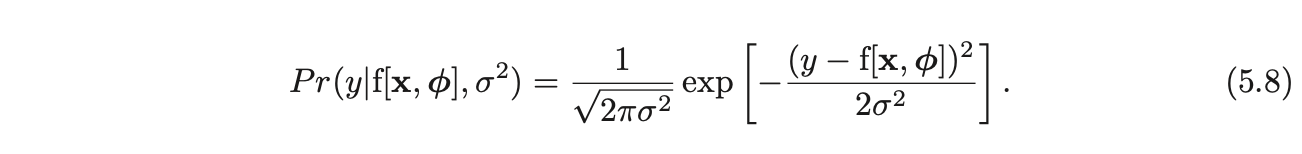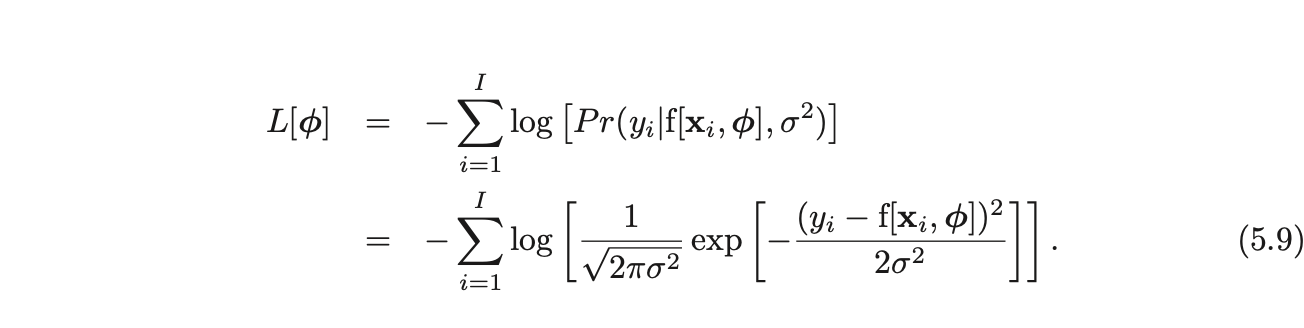Loss for univariate regression
Inference
- Predict the mean μ=f[x,ϕ] of the Normal Distribution over y
- We find the single best point estimate y^ and we take max of the predicted distribution y^=yargmax[Pr(y∣f∣x,ϕ^,σ2)]=f[x,ϕ^]
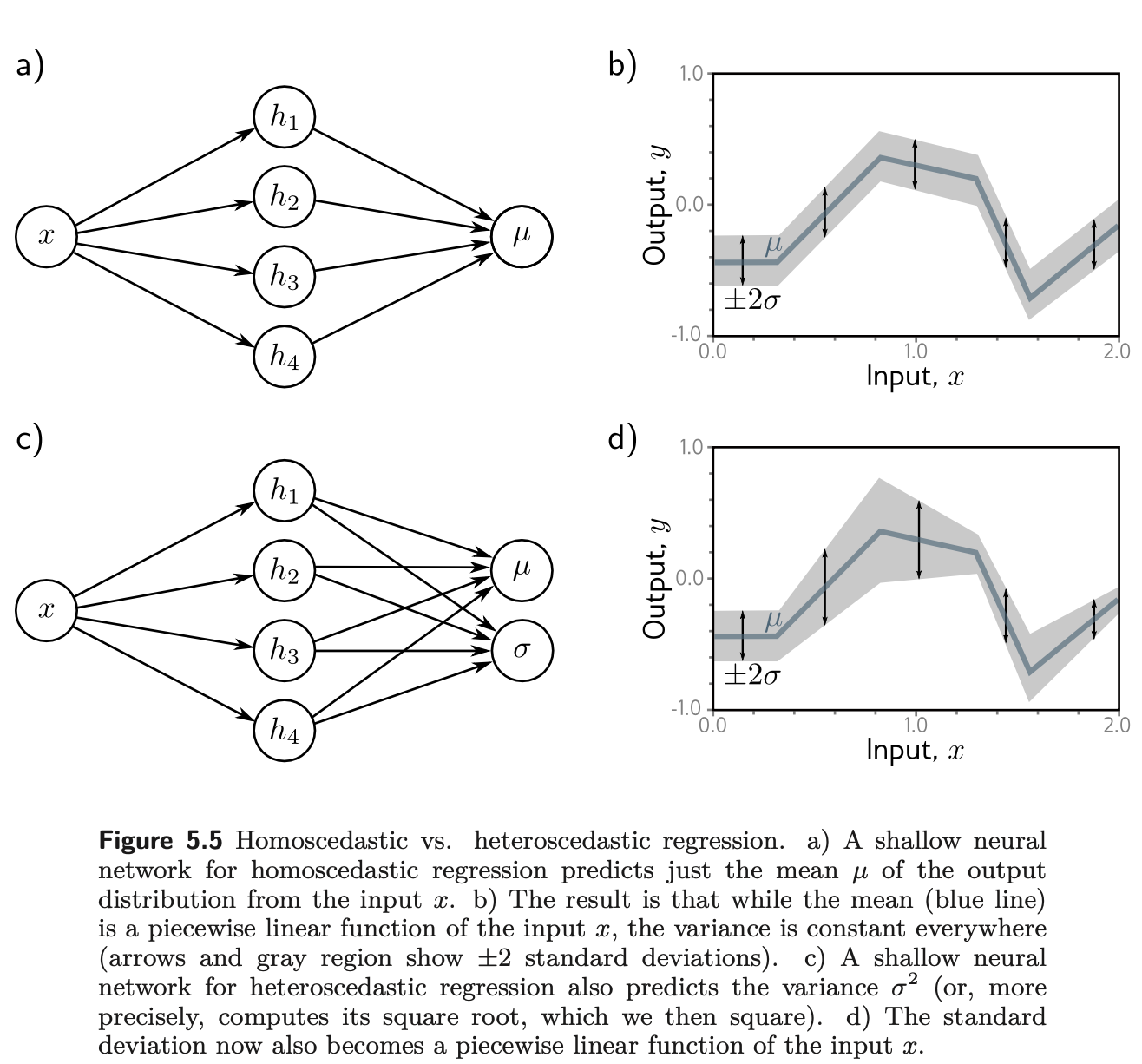
Estimating if variance constant everywhere
- Homoscedatic
- Since the equation does not depend on variance, we pretend σ2 is a learned parameter and minimize it wrt ϕ,σ2

Estimating if variance is not constant
- Heteroscedatic
- Train a network that computes both mean and variance
- Variance should be positive, but the result of composing networks might not be. To make it, pass it through the squaring function