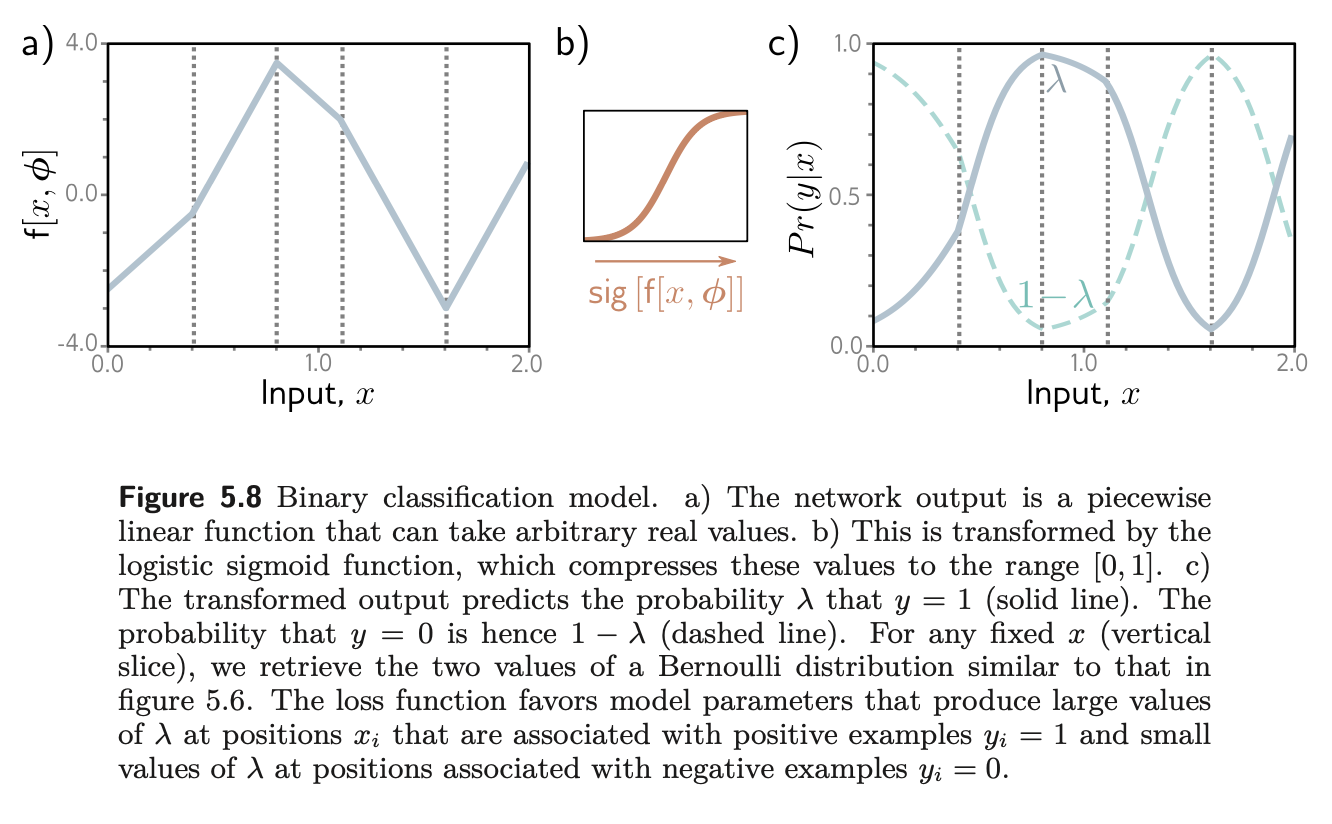
Loss for binary classification
- Two classes
- Probability distribution - Bernoulli Distribution
- Training → Model to predict , but these values might not lie in [0,1] and we need it to. → Sigmoid
- Cross Entropy

- This represents the probability that y = 1, and it follows that 1 − λ represents the probability that y = 0. When we perform inference, we may want a point estimate of y, so we set y = 1 if λ > 0.5 and y = 0 otherwise.