Word2Vec relies only on local information of language. That is, the semantics learnt for a given word, is only affected by the surrounding words.
Unsupervised Learning algorithm which captures both global statistics and local statistics of a corpus
aggregated global word co-occurrence statistics from a corpus, and the resulting representations showcase interesting linear substructures of the word vector space
whether distributional word representations are best learned from count-based methods or from prediction-based methods
probe the underlying co-occurrence statistics of the corpus
reformulated Word2Vec optimizations as a special kind of factorization for word co-occurence matrices
Note that GloVe does not use neural networks
utilizes this main benefit of count data while simultaneously capturing the meaningful linear substructures prevalent in recent log-bilinear prediction-based methods like Word2Vec
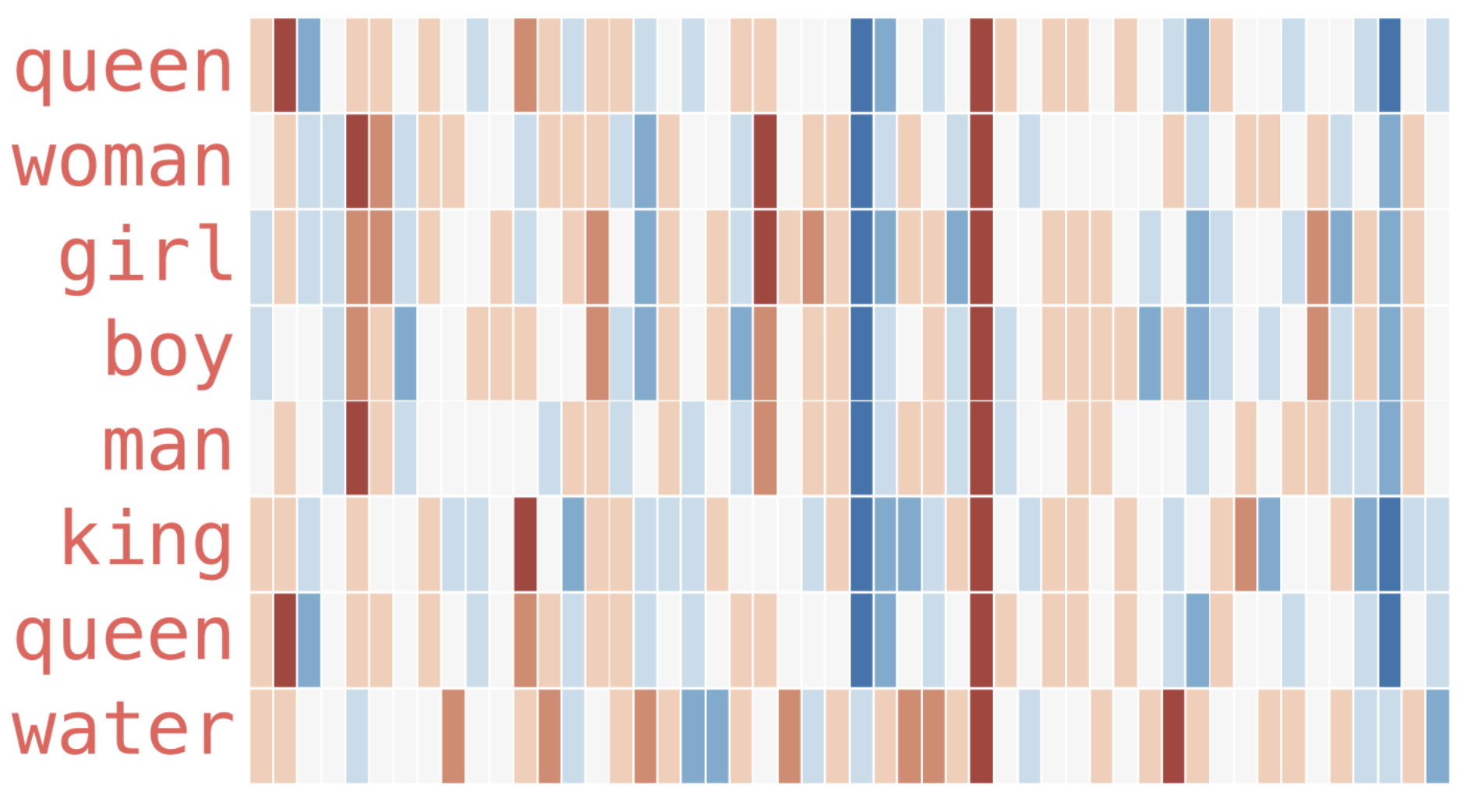
There’s a straight red column through all of these different words. They’re similar along that dimension (and we don’t know what each dimensions codes for)
There are clear places where “king” and “queen” are similar to each other and distinct from all the others. Could these be coding for a vague concept of royalty?