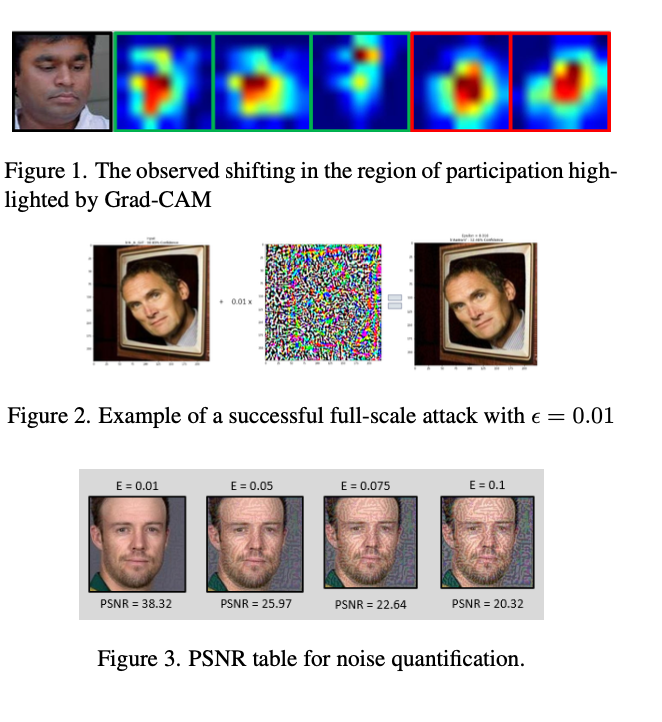
The drawback of Grad-CAM is that it cannot be used to generalize CNN behaviour.
extends Grad-CAM from example-based explanations to a method for explaining global model behaviour
These metrics are computed by comparing a Normalized Inverted Structural Similarity Index (NISSIM) metric of the Grad-CAM generated heatmap for samples from the original test set and samples from the adversarial test set.
We observe a consistent shift in the region highlighted in the Grad-CAM heatmap, reflecting its participation to the decision making, across all models under adversarial attacks.
These adversarial attacks display specific properties, i) They are not perceptible to the human eye, ii) They are controllable, and iii) Transferability, i.e., an attack designed for one model is capable of attacking multiple models
There are mainly two kinds of attacks: targeted and non-targeted attacks. Targeted attack makes a model predict a certain label for the adversarial example, while for non-targeted attacks the labels for adversarial examples are not important, as long as the model is wrong
These attacks can also be subdivided into black-box attacks and white-box attacks. Black-box attacks have no information about the target model, training procedure, architecture, whereas white-box attacks know the target model, training procedure, architecture, parameters.
The CKA-similarity algorithm was used to compare the hidden representations of broad and deep models . They found that when the model capacity is large compared to the training set, a block structure emerges, which shows that the models propagate the main component of their hidden representation.
More recent methods leverage explainability of machine learning and use SHAP based signatures to detect adversarial attacks
As a result, we observed a global pattern displayed by all models. The shifting in the region of participation can be defined as when a model sees adversarial examples. Some parts of the input image no longer participate in the decision-making, while new parts do participate.
These changes are not deterministic, and given an adversarial example, there is no way to tell how it will affect the shift
First, we preprocess the dataset to align and crop the faces. Then, the dataset is split into 80% training, 10% testing, and 10% validation sets.
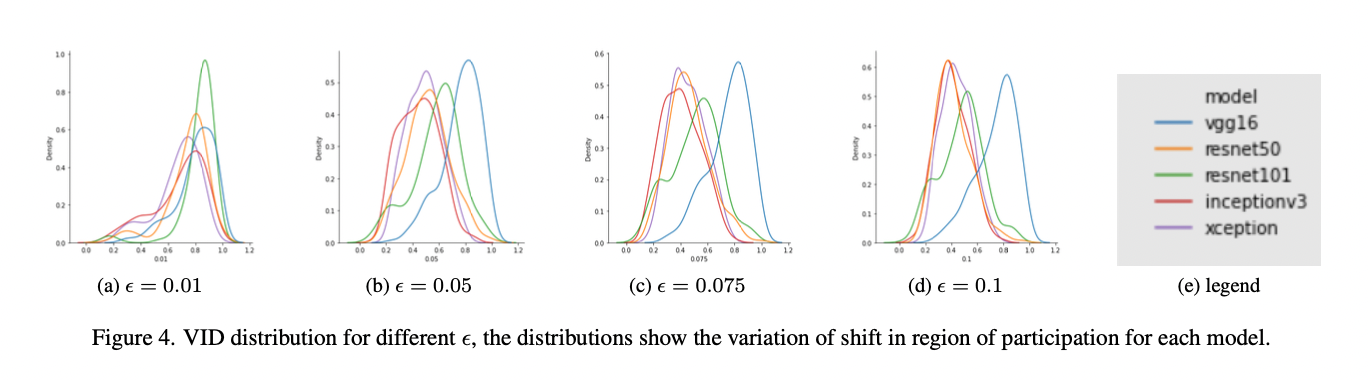
Once the training step is completed, the stored models are loaded and used to generate perturbations from the test set using FGSM.
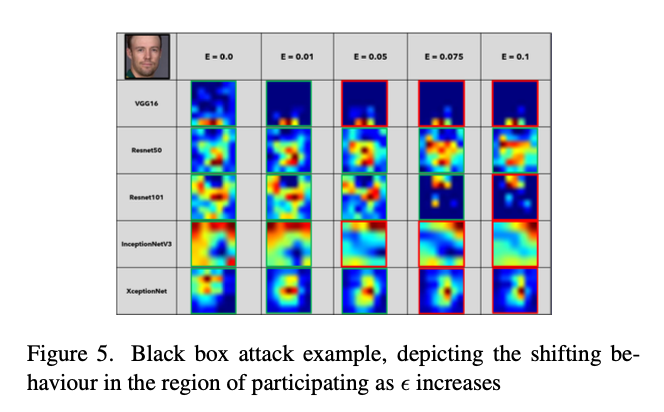
Then the test set is attacked with different values of ϵ from the stored perturbations and these counterexamples are stored as perturbed test sets
Finally, Grad- CAM was used to generate heatmaps for every layer in each model and each ϵ in the perturbed test set.
VGG 16: we can observe clearly that all the attacks were successful and illustrates a clear shift of participating regions as the ϵ increases.
ResNet50 : the number of layers are too many to pin point out some example, yet if observed very carefully the hidden layers as the ϵ increases, we can find a shifting in the region of participation.
In ResNet101: it seems more resilient there are some observable region shifts, but overall much less.
InceptionNet v3 : seems to have learnt something different, the focus was more on forehead than face, but the overall shifting is much higher for this model, we even see focus regions getting inverted as the ϵ increases.
For XceptionNet : the phenomenon is more clear, some regions get expanded, and background areas are being highlighted.
We use the heatmap obtained from the original image (without adversarial perturbation) as our ground truth heatmap, i.e., what the model expects to see in order to make a decision, then the second heatmap is generated from the adversarially attacked image, and we create a dataframe with all the NISSIM values for the entire test set comparing with the adversarial test set for all values of ϵ.
We can also use this metric to explain the performance of VGG16. Since the shift was smaller, the model was less likely to fail.
We also find that deep networks perform better than wide networks for similar shifts
The main idea, that is examined here, is that the lower the shift in distribution, more the model is robust to adversarial attacks
This indicates that VGG16 is a stable model for this task, over the other models.
Observations
We see a shift in the focus of the model in different directions, sometimes backgrounds get highlighted, other times, participation region expands or shrinks.
Deeper models are much robust to this changes, for similar amount of shift, deeper models provide better performance than wider models.
neural networks fail because of a shifting behaviour in the region of participation to the decision-making, when the model sees adversarial examples, its focus changes and it now sees a different hidden representation
The main observation to keep in mind is, as ϵ increases, the dissimilarity increases, indicating that the focus of the model is diverted when it is presented an adversarial example, this value indicates that the more the examples differ, the more likely the model will fail.
We can observe a pattern that wide models fail more than deep models as the ϵ increases