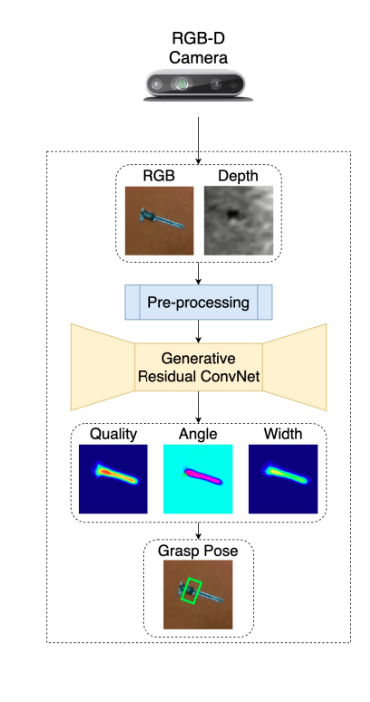
GRConvNet
- Generative Residual Convolutional Neural Network
- Learning an object agnostic function to grasp objects
- Uses multi modal input data (RGB + depth images).
- Generates pixel-wise antipodal grasp configuration.
- State-of-the-art performance (97% on Cornell dataset).
- Use eye-to-hand camera configuration.
- Sulabh Kumra, et al. “Antipodal robotic grasping using generative residual convolutional neural network.” IROS 2020.