Embedding Human Knowledge into Deep Neural Network via Attention Map
@mitsuharaEmbeddingHumanKnowledge2019
Intro
focus on the attention mechanism of an attention branch network (ABN)
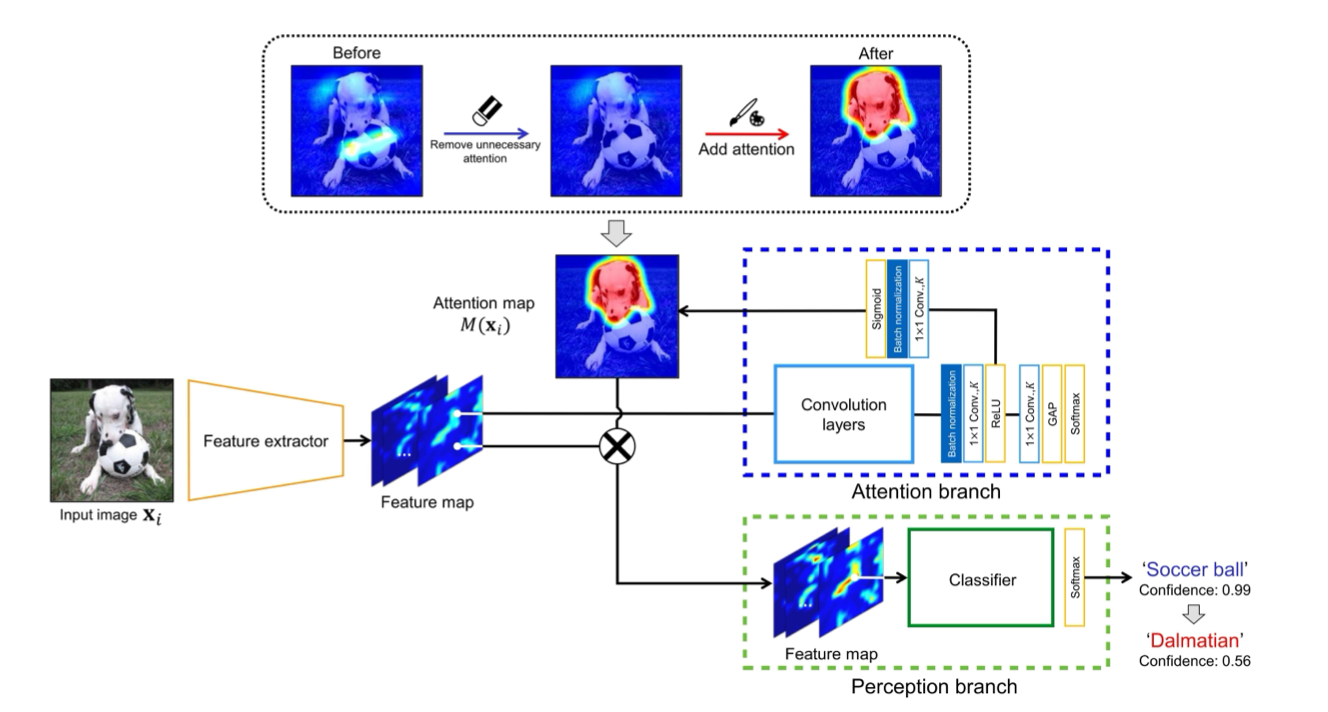
propose a fine-tuning method that utilizes a single-channel attention map which is manually edited by a human expert.
Our fine-tuning method can train a network so that the output attention map corresponds to the edited ones. As a result, the fine-tuned network can out- put an attention map that takes into account human knowl- edge
human intuitive edit- ing via a visual interface and suggest new possibilities for human-machine cooperation in addition to the improvement of visual explanations.
Typical visual explanation approaches in- clude class activation mapping (CAM) and Grad-CAM
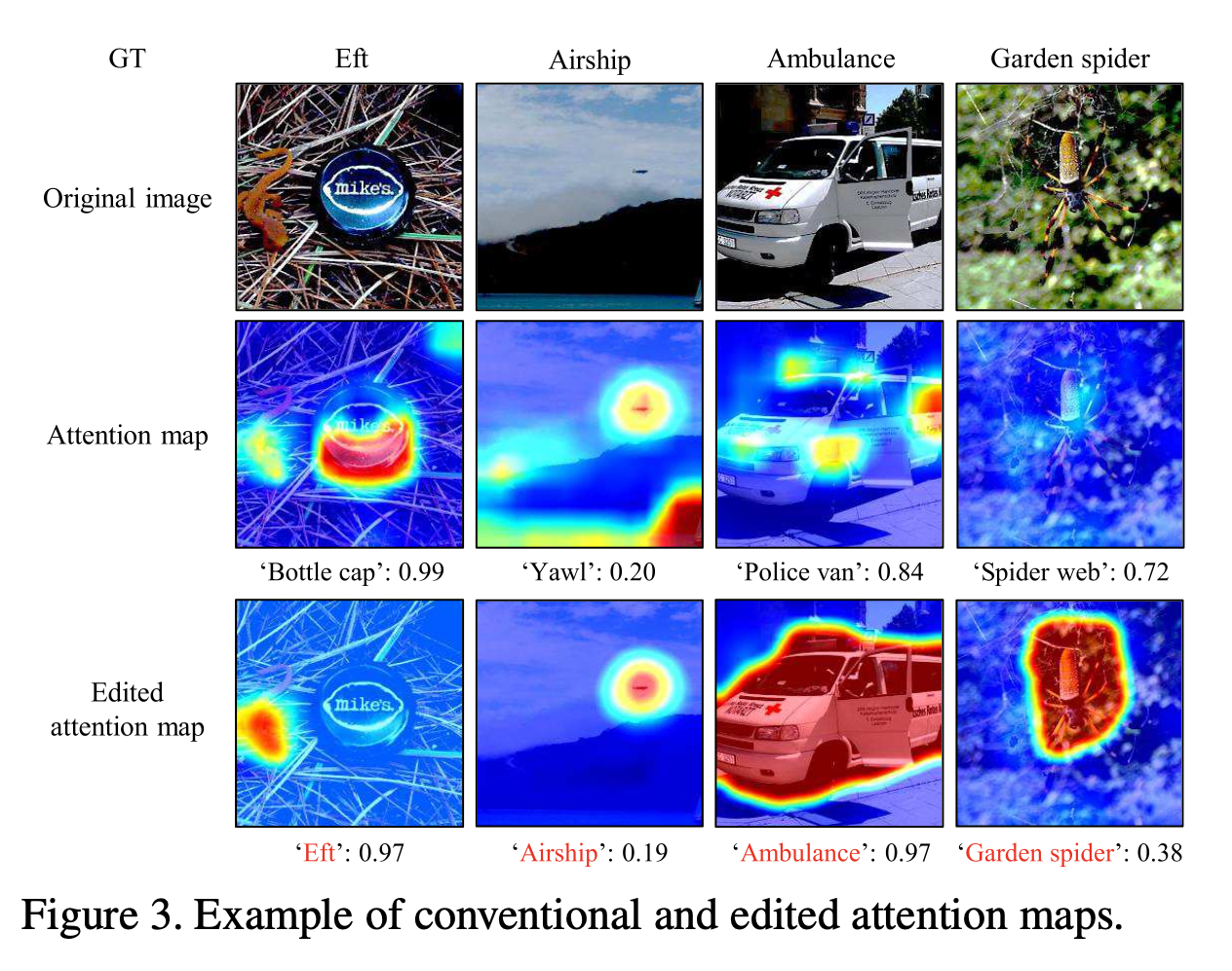
However, an inconsistency between the tar- get region of the recognition result, namely the ground truth (GT), and an attention region may occur.
To this end, we focus on the visual explanation and the attention mechanism of ABN
ABN applies an atten- tion map for visual explanation to the attention mechanism.
We propose a fine-tuning method based on the characteristics of ABN and an edited attention map
The proposed method fine-tunes the attention and perception branches of ABN to output the same attention map as the edited one.
Related Work
Embedding Human Knowledge
human-in-the- loop (HITL)
Branson et al. [4] pro- posed an interactive HITL approach that helps to train a decision tree by using a question and answer with respect to a specific bird.
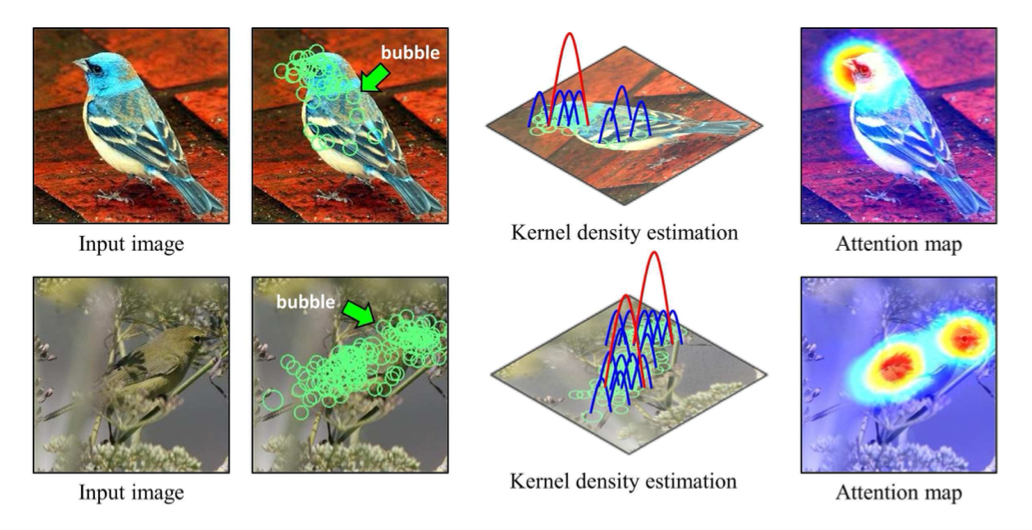
Deng et al. [7] used a bubble, that is, a circular bounding box, as human knowl- edge. This bubble information is annotated from an atten- tion region when a user distinguishes the two types of birds. By annotating the bubble with various pairs and users, char- acteristic regions of bird images can be obtained when we recognize bird categories.
Linsley et al. [18] proposed a method that incorpo- rates human knowledge into large-scale deep neural net- works using the HITL framework. This method added a spatial attention mechanism into the attention mecha- nism [19, 15, 13, 2, 20, 35, 33, 37, 39, 40] of squeeze-and- excitation networks (SENet) [13] and trained the network by using a ClickMe map that introduces human knowledge to the weights of the attention mechanism.
Editing the Attention Map
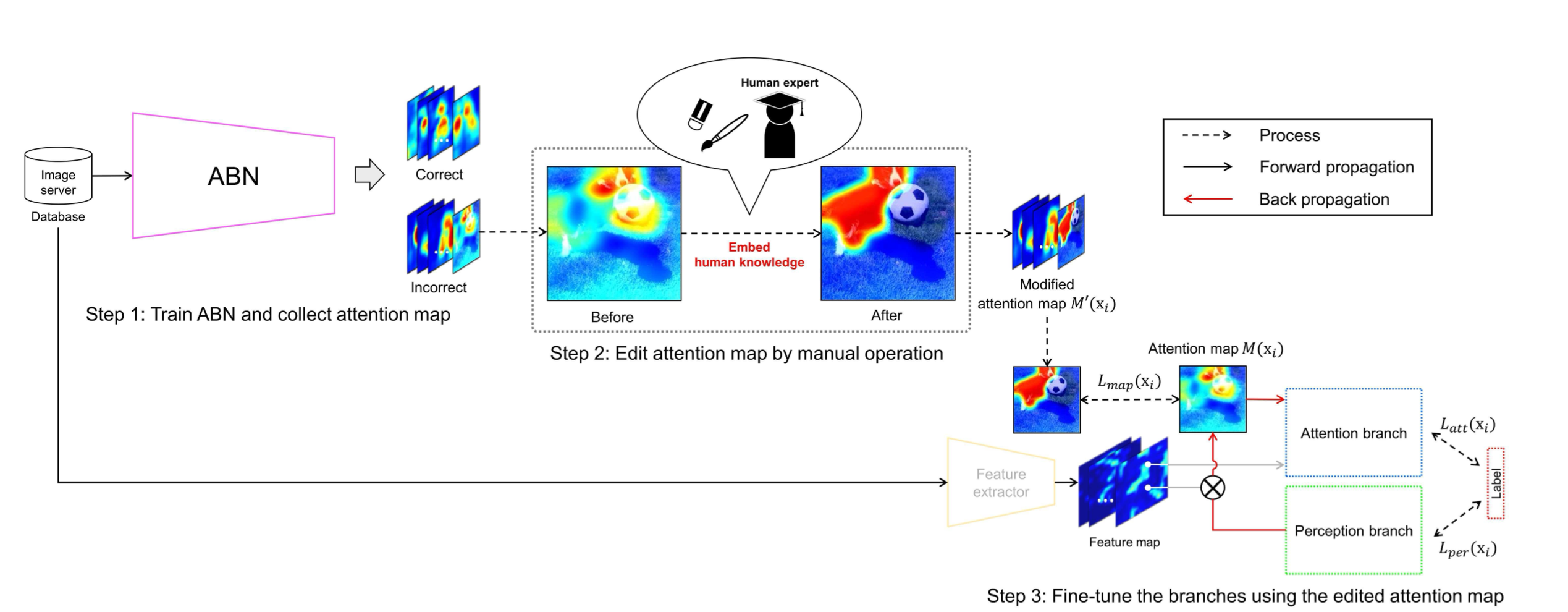
In this experiment, we used an ABN whose backbone is 152-layer ResNet [12] (ResNet152+ABN) as a network mode
Then, we selected the 1k misclassified samples from the validation samples and edited the maps
btain the attention map from the at- tention branch, where the size of the attention map is 14×14 pixels. Then, we edit the obtained attention map manually. Note that the attention map is resized to 224×224 pixels and is overlaid with the input image for ease of manual editing. The edited attention map is resized to 14 × 14 pixels and used for an attention mechanism to infer classification re- sults from the perception branch.
By training the attention and percep- tion branches with the edited attention map including hu- man knowledge, ABN can output an attention map that con- siders this knowledge and thereby improve the classification performance.
During the fine-tuning process, we update the parameters of the attention and perception branches by using the loss calculated from the attention map obtained from ABN and the edited attention map in addition to the loss of ABN
To make an attention map from the bubbles, we use a kernel Density estimation with multiple bubbles
A dense region of bubbles indicates an impor- tant region for recognizing the bird category.
In contrast, the proposed method highlights the local characteristic regions, such as the color and the head of the bird. In addition, the proposed method removes noise from the attention map by fine-tuning. Thus, the proposed method can also improve the performance of fine-grained recognition.
Consequently, our method can gener- ate a more interpretable attention map and successfully em- bed human knowledge.
Fine Tuning Branches
xi is the i-th sample
Labn(xi)=Latt(xi)+Lper(xi)
- where $L_{arr}, L_{per}$ are conventional cross entropy losses for the attention and perception branches, respectively
L(xi)=Labn(xi)+Lmap(xi)
Edited map : M’
Lmap(xi)=γ∣∣M′(xi)−M(xi)∣∣2
- $\gamma$ is a scale factor
- $L_{map}$ is larger than the others, hence needs to be scaled