They captured the discriminative areas of the input image by considering the activation of high and low spatial scales in the Fourier space.
“Deep,” because it is the development and performance of deep neural network models that we want to understand. “Visual,” because we believe that the most rapid insight into a complex multi-dimensional model is provided by appropriate visualization techniques, and “Explanation,” because in the spectrum from instrumentation by inserting print statements to the abductive inference of explanatory hypotheses, we believe that the key to understanding deep learning relies on the identification and exposure of hypotheses about the performance behavior of a learned deep model.
Deep convolutional neural networks (DCNN) produce spatial information at the convolution layers
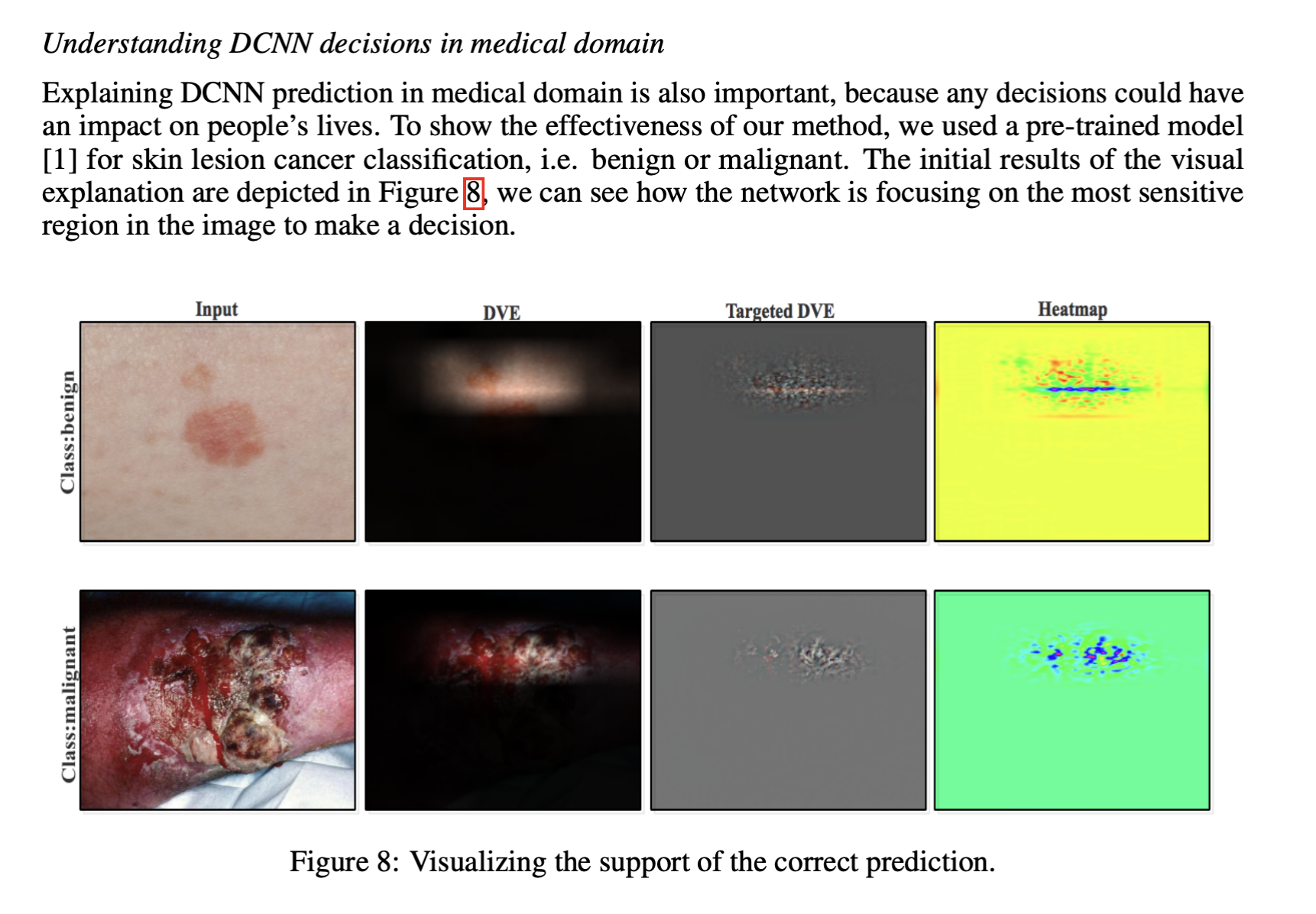
loss of information makes the explanation process challenging, especially when it comes to interpreting the output of sensitive data such as medical images
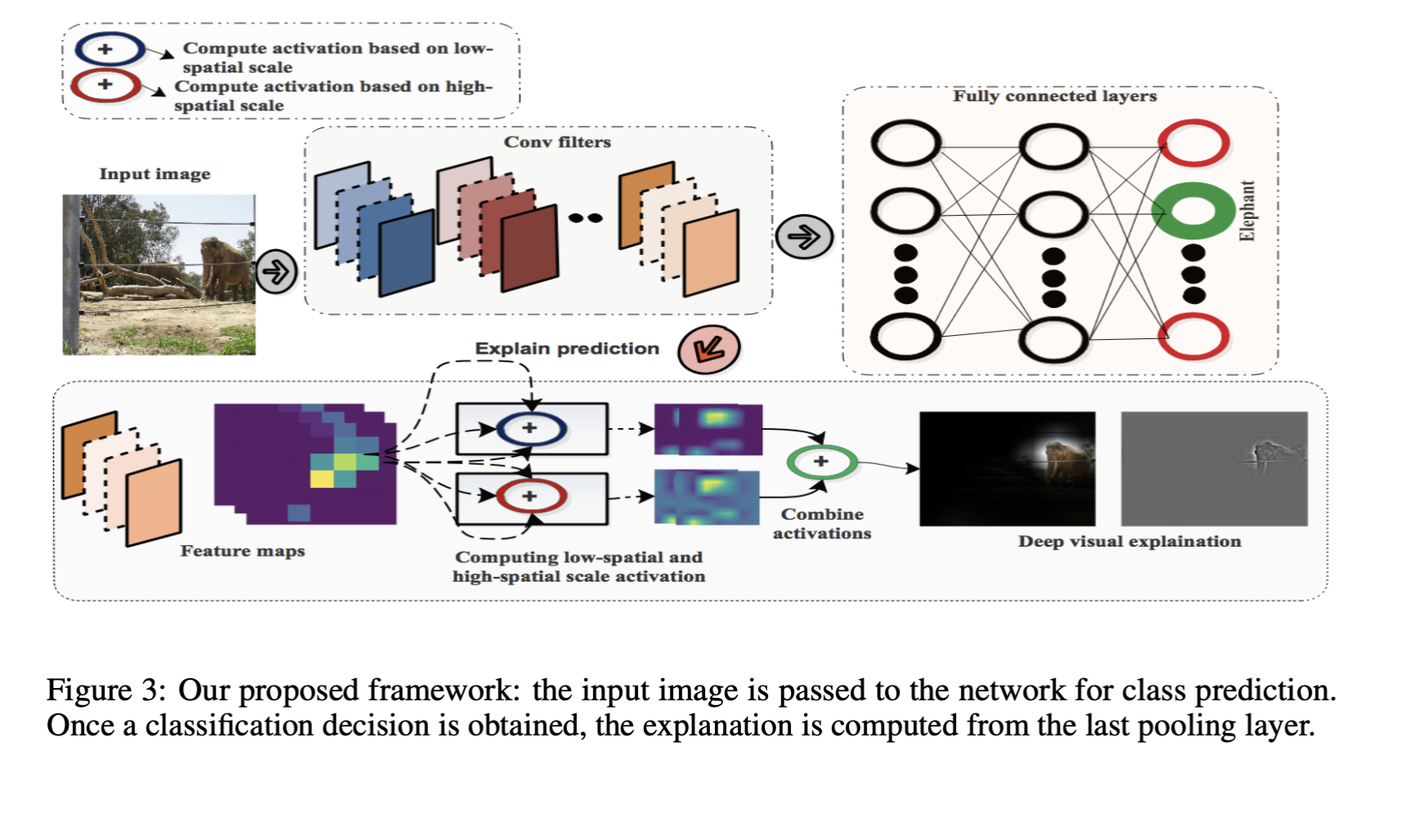
Our immediate goal is to create an explanation about the outcome of a DCNN, i.e., to identify which discriminative pixels in the image influence the final prediction
To approach this task in this restricted context, we assume that the convolution feature maps X at pooling layer l contain some relevant information about class y
We can then write our solution as: D:I→yi→S i.e., map the input I to class yi using network D, and compute the evidence/explanation S
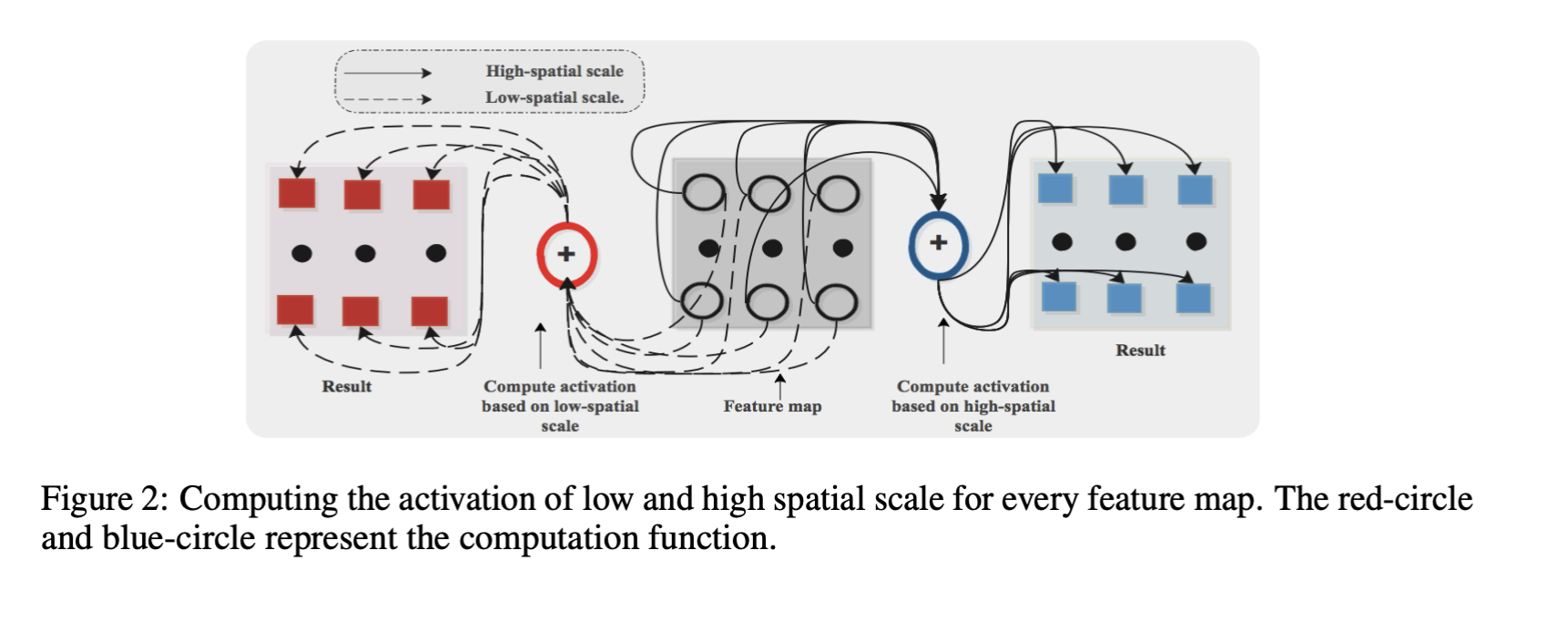
output. So to explain yi→S, we can compute the low-spatial scale and high-spatial scale activations of every feature map
Visual Explanation
Explanaton in Fourier domain. Function F(x) represents transform with x∈R , x is a feature map at a conv layer
For every xi∈X of size M×N , the transform can be written as $$
F(u,v) = \Sigma_{k=0}^{M-1} \Sigma_{j=0}^{N-1}f(k,j)e^{-i2\pi(\frac{uk}{M}+ \frac{vj}{N})}
- $f(k,j)$ is feature map at layer $l$
- exp term is the basis function
- inverse of fourier is $$
f(m,n) = \frac{1}{M\times N} \Sigma_{u=0}^{M-1} \Sigma_{v=0}^{N-1}F(u,v)e^{i2\pi(\frac{ux}{M}+ \frac{vy}{N})}
For every feature map, xi∈X, visual explanation is $$
S = \Sigma_{i=1}F^{-1}(F(x_{i} * G_{1}) * F^{-1}(F(x_{i})*(1-G_{2})))
- $G_{1}, G_{2}$ are Guassians at different $\sigma$ values,
- Low spatial scale activation $F(x_{i})*G_{1}$
- High scale activation $F^{-1}(F(x_{i})*(1-G_{2}))$
- 
## Targeted Deep Visual Explanation
- In our simple case of image classification (cf. speech, language) one of the ultimate goals of the visual explanation in the context of debugging is to be precise when determining the component salient patch.
- Therefore, we should penalize any activations that do not contribute much
- To handle this, we propose a method called targeted-DVE to provide a more targeted explanation. This algorithm removes any pixel that has less influence on the best explanation
- The process is identical to our previous approach except that, we slightly modify the final output S obtained in Algorithm 1. This is done, by computing S0 as follows
- $$S' = F^{−1}(F(S) * G_{1}) * F^{−1}(F(S * (1 − G_{2}))
Our approach captures the discriminative pixels by considering the activation of high and low spatial scales in Fourier space.
We experimented with a simple version of our approach on image classification.