Deep Inside Convolutional Networks
-
Karen Simonyan, Andrea Vedaldi, Andrew Zisserman
-
@simonyanDeepConvolutionalNetworks2014
-
Because the word saliency is often related to the whole approach to display input attribution called Saliency Map, this method is also known as Vanilla Gradient
-
finding L2 regularized image III that maximizes score for a given class c
-
It can be written formally as:
-
-
Where is a regularisation parameter
-
To find the value of I, we can use the back-propagation method. Unlike in the standard learning process, we are going to back-propagate with respect to the input image, not the first convolution layer
From class visualization to Saliency
- This idea can be extrapolated, and with minor modifications, we should be able to query for spatial support of class ccc in a given image I0I_0I0.
- rank pixels of in relation to their importance in predicting score
- Authors assume that we can approximate with a linear function in the neighborhood of
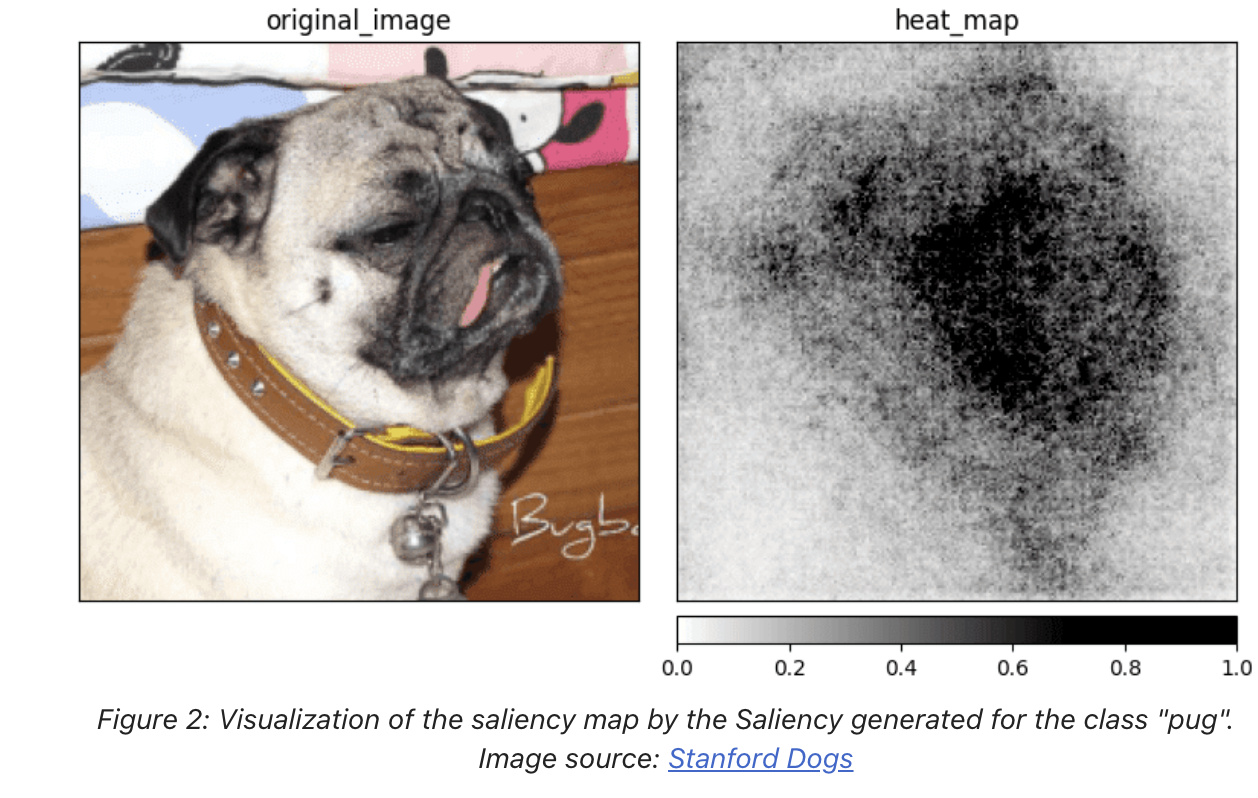
- For a pair of input image and the class c, we are able to compute saliency map (where m and n are the height and width of the input in pixels).
- compute derivative w and rearrange elements in the returned vector.
- uses different approaches base on the number of channels in the input image .
- For grey-scale pixels (one color channel), we can rearrange the pixels to match the shape of the image
- If the number of channels is greater than one, we are going to use the maximum value from each set of values related to the specified pixel.
- ch is a color channel of the pixel (i,j) and h(i,j,ch) is an index of the www corresponding to the same pixel (i,j).
- The original Saliency method produces a lot of additional noise but still gives us an idea of which part of the input image is relevant when predicting a specific class.
- This often causes a problem when the object on the image has a lot of details and the model is using most of them to make a prediction.