Contributions of Shape, Texture, and Color in Visual Recognition Abstract
/zotero
Yunhao Ge, Yao Xiao, Zhi Xu, Xingrui Wang, and Laurent Itti
Abstract
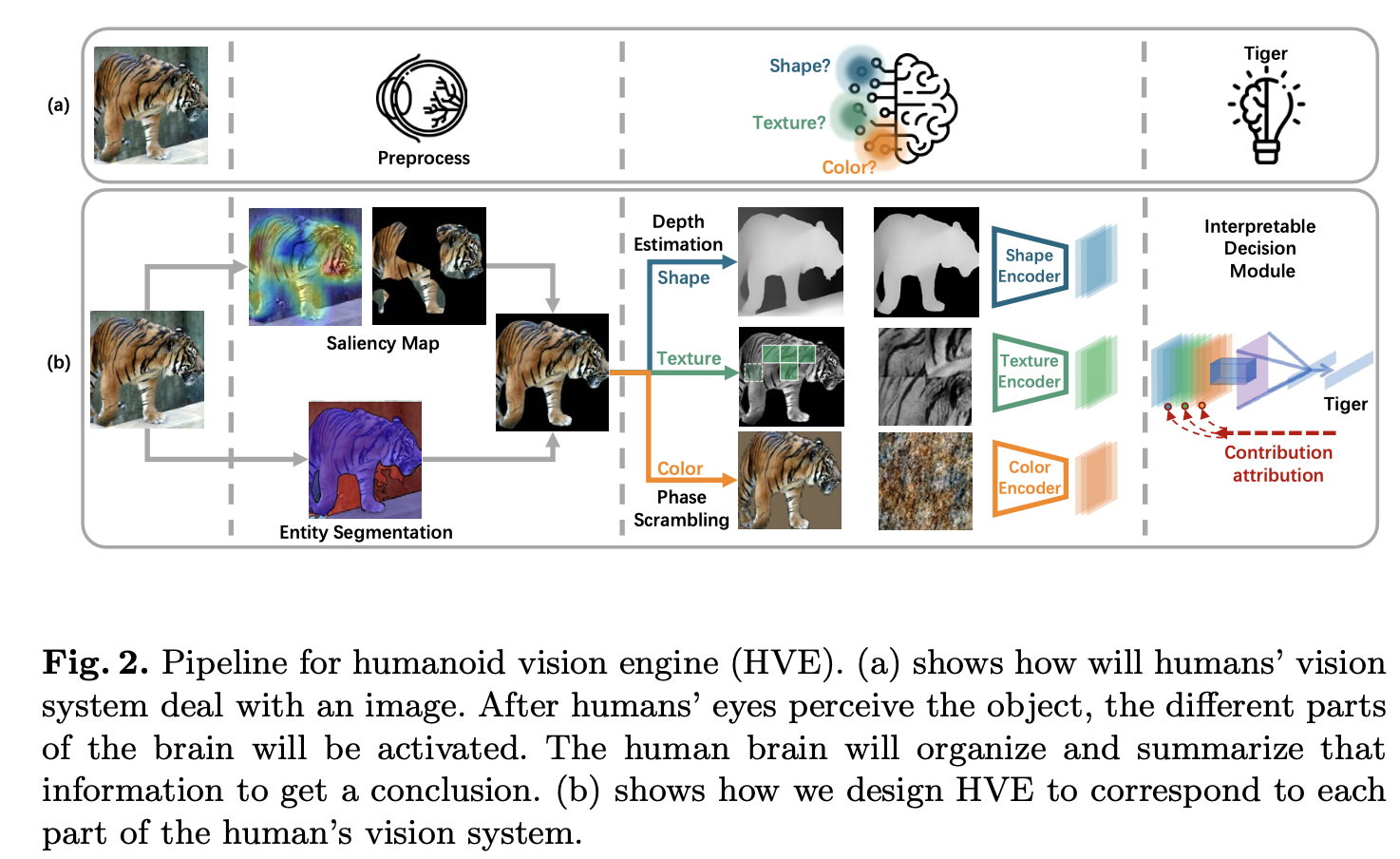
[humanoid vision engine](humanoid vision engine.md) (HVE) that explicitly and separately computes shape, texture, and color features from images
resulting feature vectors are then concatenated to support the final classification
HVE can summarize and rankorder the contributions of the three features to object recognition.
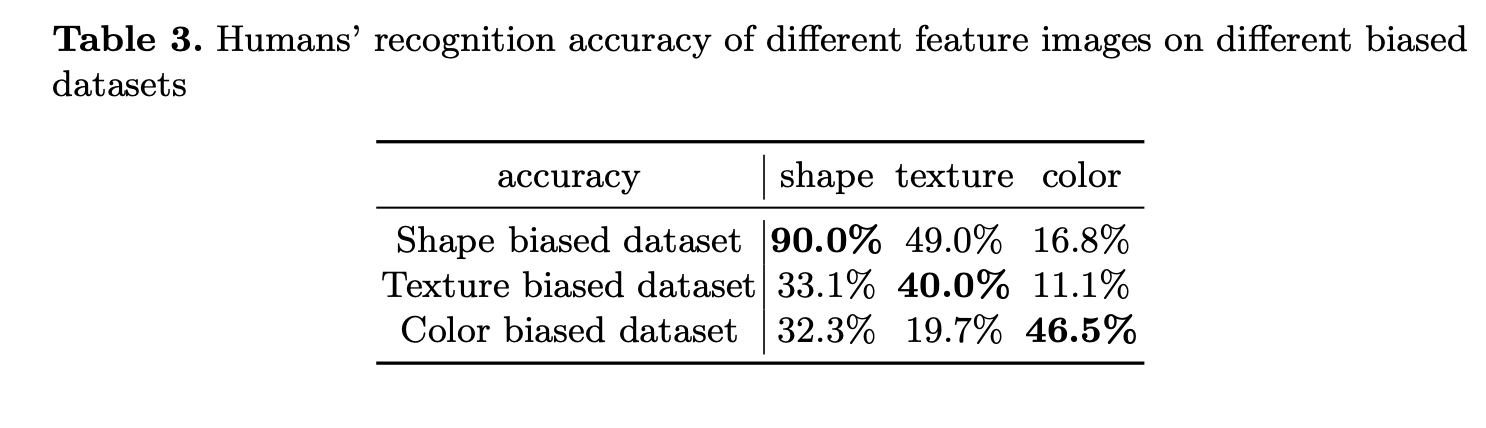
We use human experiments to confirm that both HVE and humans predominantly use some specific features to support the classification of specific classes
To demonstrate more usefulness of HVE, we use it to simulate the open-world zeroshot learning ability of humans with no attribute labeling
Finally, we show that HVE can also simulate human imagination ability with the combination of different features.
Introduction
A widely accepted intuition about the success of CNNs on perceptual tasks is that CNNs are the most predictive models for the human ventral stream object recognition
To understand which feature is more important for CNN-based recognition, recent paper shows promising results: ImageNet-trained CNNs are biased towards texture while increasing shape bias improves accuracy and robustness [33]
Here, inspired by HVS, we wish to find a general way to understand how shape, texture, and color contribute to a recognition task by pure data-driven learning.
It has been shown by neuroscientists that there are separate neural pathways to process these different visual features in primate
Among the many kinds of features crucial to visual recognition in humans, the shape property is the one that we primarily rely on in static object recognition [16]. Meanwhile, some previous studies show that surface-based cues also play a key role in our vision system
For example, [21] shows that scene recognition is faster for color images compared with grayscale ones
we use the entity segmentation method [41] to simulate the process of parsing objects from a scene in our brain.
Entity segmentation is an open-world model and can segment the object from the image without labels.
This method aligns with human behavior, which can (at least in some cases; e.g., autostereograms [29]) segment an object without deciding what it is
After we get the segmentation of the image, we use a pre-trained CNN and Grad-CAM [47] to find the foreground object among all masks.
We design three different feature extractors after identifying the foreground object segment: shape extractor, texture extractor, and color extractor, similar to the separate neural pathways in the human brain which focus on specific property
Shape Feature Extractor
want to keep both 2D and 3D shape information while eliminating the information of texture and color
first use a 3D depth prediction model [44,43] to obtain the 3D depth information of the whole image
After element-wise multiplying the 3D depth estimation and 2D mask of the object, we obtain our shape feature
We can notice that this feature only contains 2D shape and 3D structural information (the 3D depth) and without color or texture information
Texture Feature Extractor
want to keep both local and global texture information while eliminating shape and color information.
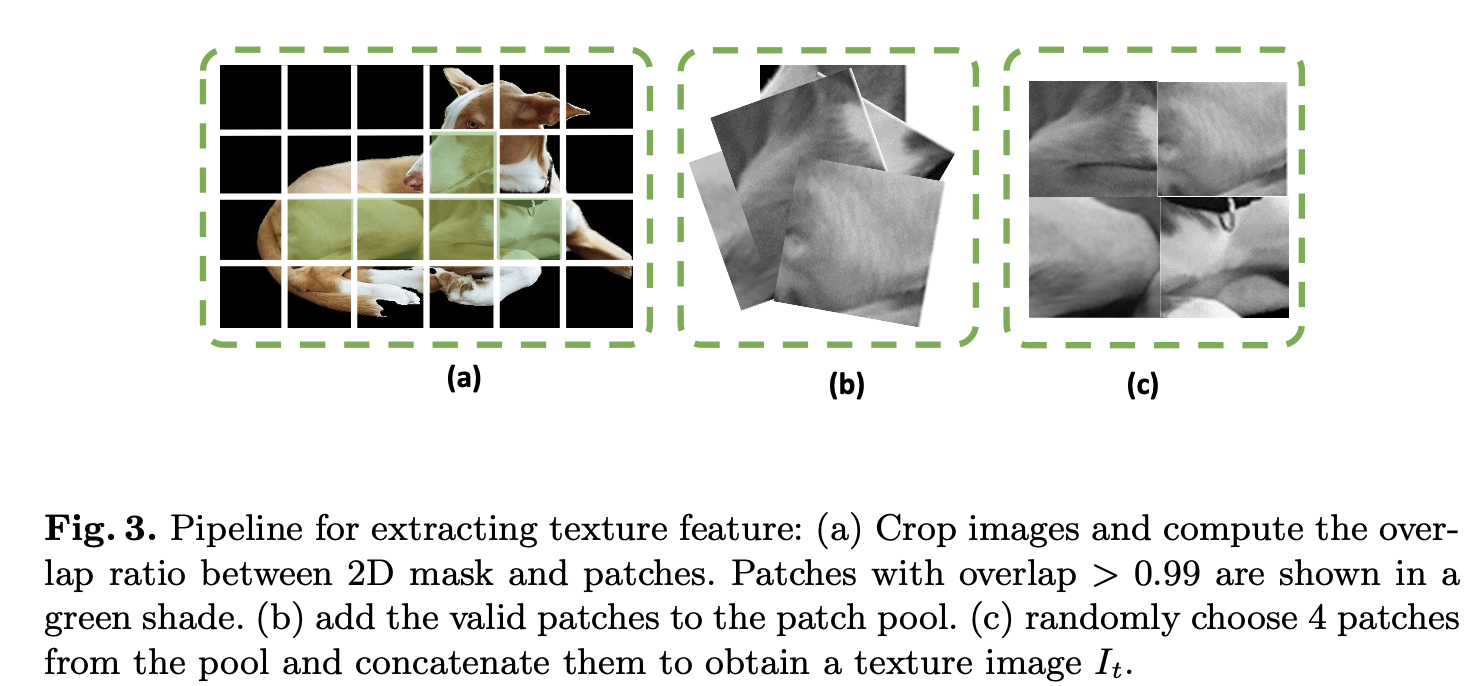
to remove the color information, we convert the RGB object segmentation to a grayscale image
cut this image into several square patches with an adaptive strategy (the patch size and location are adaptive with object sizes to cover more texture information)
If the overlap ratio between the patch and the original 2D object segment is larger than a threshold τ, we add that patch to a patch pool (we set τ to be 0.99 in our experiments, which means the over 99% of the area of the patch belongs to the object
Since we want to extract both local (one patch) and global (whole image) texture information, we randomly select 4 patches from the patch pool and concatenate them into a new texture image
Color Feature Extractor
The first method is phase scrambling
Phase Scrambling
transforms the image into the frequency domain using the fast Fourier transform (FFT)
In the frequency domain, the phase of the signal is then randomly scrambled, which destroys shape information while preserving color statistics
Then we use IFFT to transfer back to image space
We also used simple color histograms (see suppl.) as an alternative, but the results were not as good, hence we focus here on the phase scrambling approach for color representation.
Humanoid Neural Network
After preprocessing, we have three features
To simulate the separate neural pathways in humans’ brains for different feature information [1,11], we design three feature representation encoders for shape, texture, and color, respectively
ResNet-18 [24] as the backbone for all feature encoders to project the three types of features to the corresponding well-separated embedding spaces.
hard to define the ground-truth label of the distance between features.
Given that the objects from the same class are relatively consistent in shape, texture, and color, the encoders can be trained in the classification problem independently instead, with the supervision of class labels.
fter training our encoders as classifiers, the feature map of the last convolutional layer will serve as the final feature representation
We also propose a gradient-based contribution attribution method to interpret the contributions of shape, texture, and color to the classification decision,
Take the shape feature as an example, given a prediction p and the probability of
class k, namely pk, we compute the gradient of pk with respect to the shape feature Vs
gradient as shape importance weights ↵sk
In other words, Ssk represents the “contribution” of shape feature to classifying this
image as class k
Effectiveness of Feature Encoders
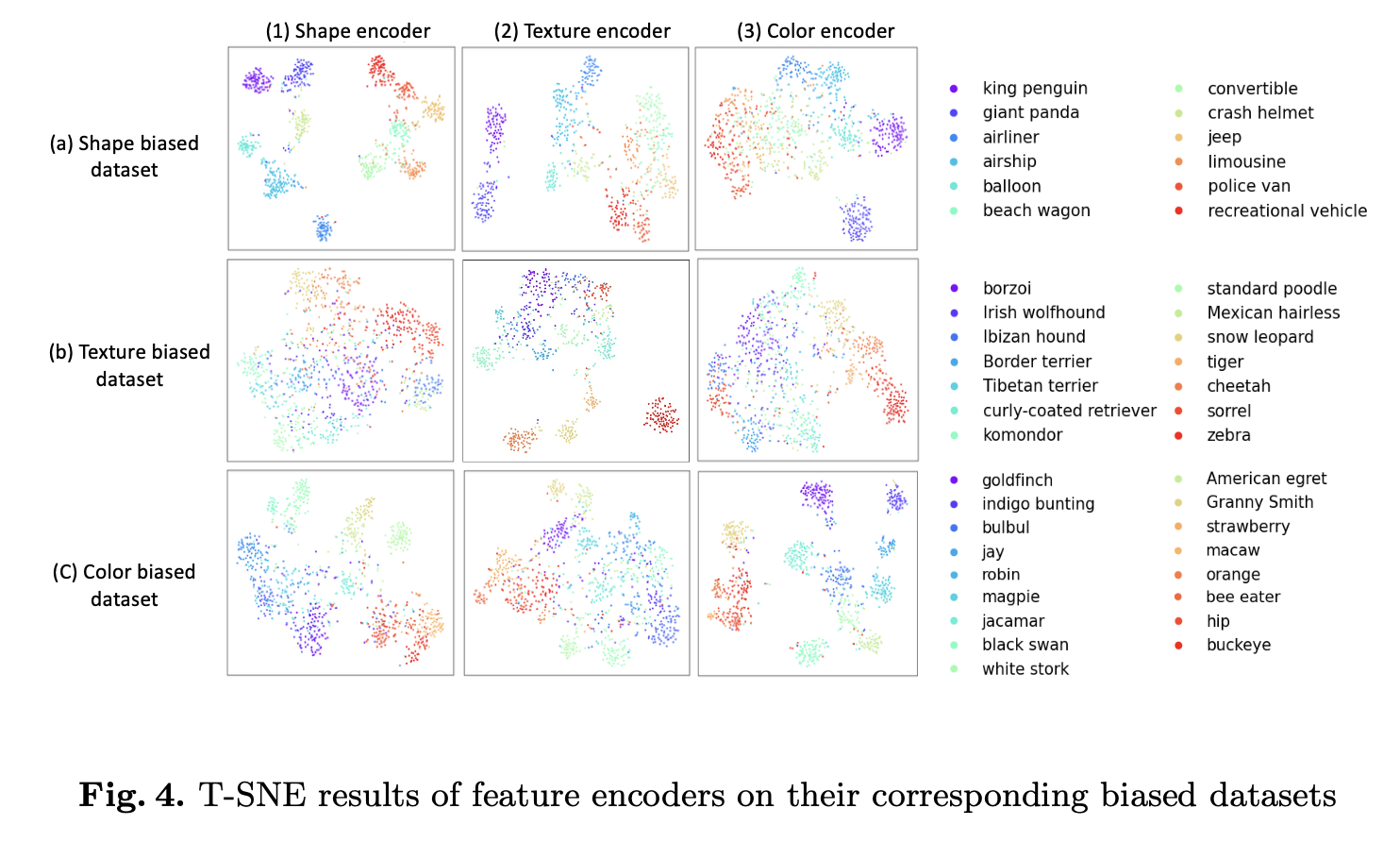
handcrafted three subsets of ImageNet
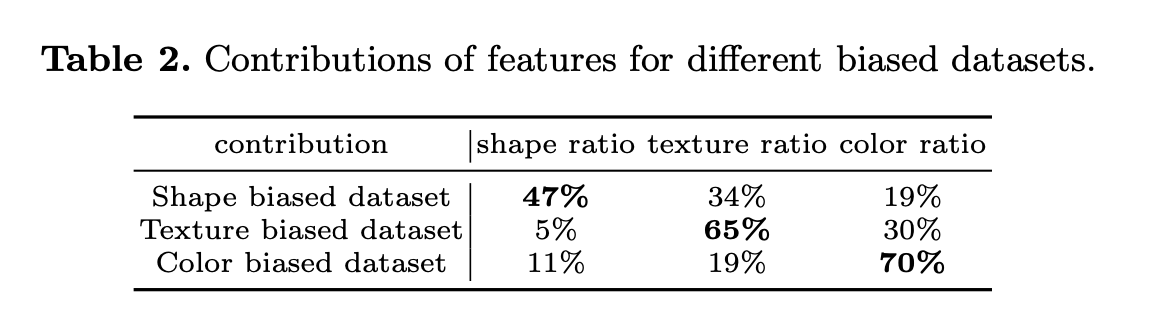
Shape-biased dataset containing 12 classes, where the classes were chosen which intuitively are strongly determined by shape
Texture-biased dataset uses 14 classes which we believed are more strongly determined by texture
Color-biased dataset includes 17 classes
After pre-processing the original images and getting their feature images, we input the feature images into feature encoders and get the T-SNE
Each row represents one feature-biased dataset and each column is bounded with one feature encoder, each image shows the results of one combination
Effectiveness of Humanoid Neural Network
As these classifiers classify images based on corresponding feature representation, we call them feature nets.
If we combine these three feature nets with the interpretable aggregation module, the classification accuracy is very close to the upper bound, which means our vision system can classify images based on these three features almost as well as based on the full original color images.
More Humanoid Applications with HVE Open-world Zero-shot Learning with HVE
Most current methods [37,32,13] need humans to provide detailed attribute labels for each image, which is costly in time and energy. However, given an image from an unseen class, humans can still describe it with their learned knowledge
First, to represent learnt knowledge, we use feature extractors
To retrieve learnt classes as description, we calculate the average distance dkm
between Iun and images of other class k in the latent space on feature m Open-world classification
To further predict the actual class of Iun based on the feature-wise description, we use ConceptNet as common knowledge to conduct reasoning
We form a reasoning root pool R⇤ consisting of feature roots Rs, Rt, Rc obtained during image description, and shared attribute roots Ras , Rat , Rac . The reasoning roots will be our evidence for reasoning
We humans can intuitively imagine an object when seeing one aspect of a feature, especially when this feature is prototypical (contribute most to classification)
For instance, we can imagine a zebra when seeing its stripe (texture). This process is similar but harder than the classical image generation task since the input features Modality here dynamic which can be any feature among shape, texture, or color
Cross Feature Retrieval
In order to reasonably retrieve the most possible other two corresponding features given only one feature (among shape, texture, or color), we learn a feature agnostic encoder that projects the three features into one same feature space and makes sure that the features belonging to the same class are in the nearby regions.
In the retrieval process, given any feature of any object, we can map it into the cross feature embedding space by the corresponding encoder net and the feature agnostic net
Then we apply the 2 norm to find the other two features closest to the input one as output. The output is correct if they belong to the same class as the input.
Cross Feature Imagination
To stimulate imagination, we propose a crossfeature imagination model to generate a plausible final image with the input and retrieved features
Inspired by the pixel2pixel GAN[26] and AdaIN[25] in the style transfer, we design a crossfeature pixel2pixel GAN model to generate the final image.