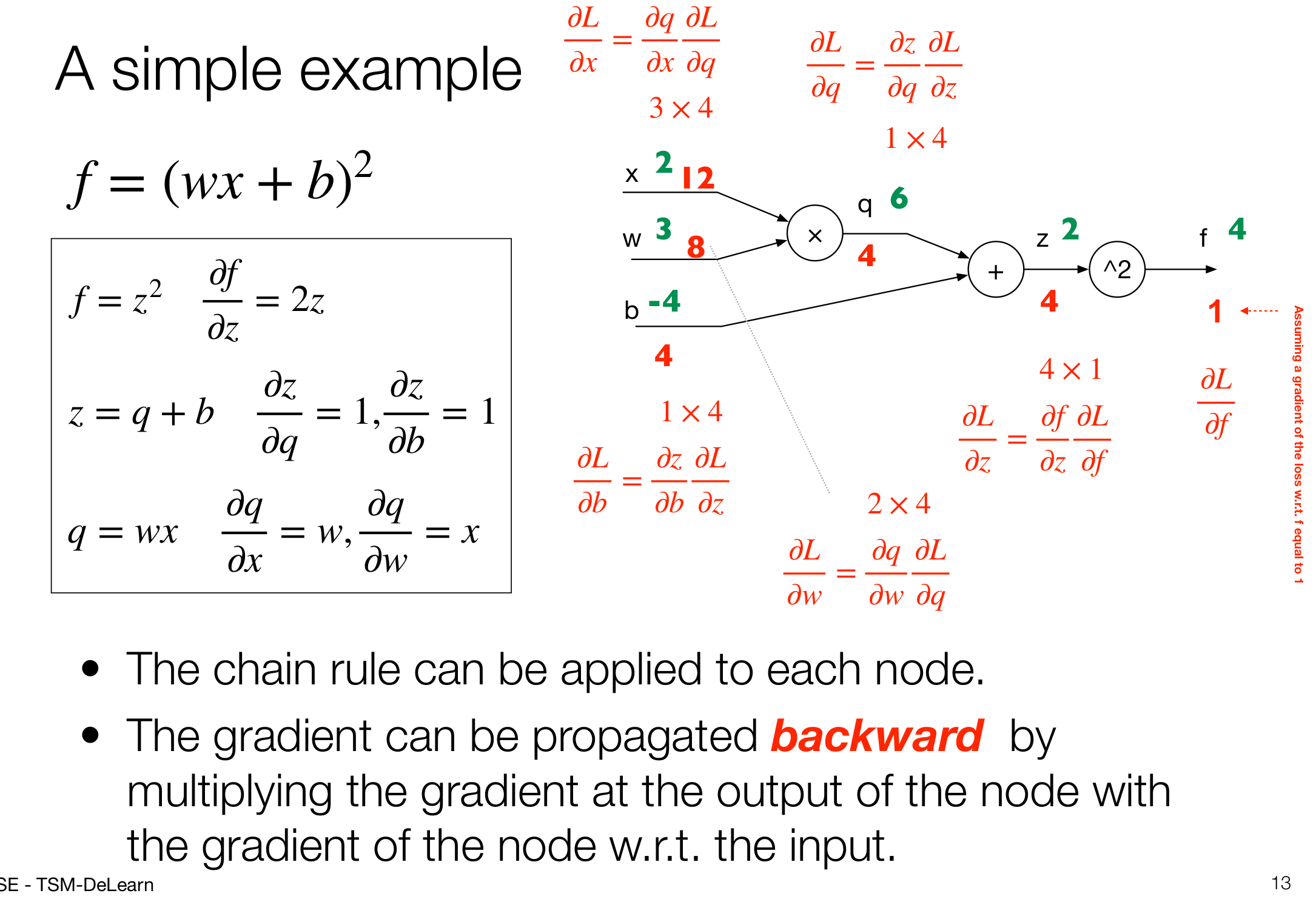
Computational Graph
- patterns in backward flow
- add gate: gradient distributor
- max gate: gradient router
- mul gate: gradient switcher
- branches: sum up gradients
- pros
- intuitive interpretation of gradient
- easily define new nodes using forward/backward pattern (i.e. only these two functions must be implemented)
- any complex learning architecture can be composed of atomic nodes (node composition or factorization)
- no need to compute manually complex gradients
- loss function can be seen as extra nodes in the end of the graph