Comparing Data Augmentation Strategies for Deep Image Classification
Sarah O’Gara and Kevin McGuinness
Summary
Inject augmentation around 30 epochs
Use learning rate decay
[Random Erasing](Random Erasing.md) is useful
Use [Adam] + [SGD](Adam] + [SGD.md)
Abstract
More complex augmentation methods have recently been developed, but it is still unclear which techniques are most effective, and at what stage of the learning process they should be introduced.
The most accurate results in all experiments are achieved using random erasing due to its ability to simulate occlusion
reducing the number of training examples significantly increases the importance of augmentation
improvements in generalization from augmentation do not appear to be only as a result of augmentation preventing overfitting
learning curriculum that injects augmentation after the initial learning phase has passed is more effective than the standard practice of using augmentation throughout, and that injection too late also reduces accuracy
We find that careful augmentation can improve accuracy by +2.83% to 95.85% using a ResNet model on CIFAR-10 with more dramatic improvements seen when there are fewer training examples
Model and Optimizer
ResNet
[He et al., 2015] presents an adaption of the model (ResNet-56) for use with 32×32 images that obtained an error rate of 6.97% on CIFAR-10, which we adopt in our experiments
SGD with Nestrov momentum
Although there are more sophisticated first order optimizers (e.g. Adam [Kingma and Ba, 2015]) that consistently improve the loss faster in the initial epochs, SGD has been observed to reach a local minima with lower overall loss and better generalization properties [Ruder, 2016]
randomly sample the dataset to create a 200 samples per class and 1,000 samples per class dataset, reducing the training examples available to 4% and 20% of the original dataset
The effects of overfitting and model generalization as noted in [Hussain et al., 2018, Shijie et al., 2017] are more pronounced with data scarcity
We introduce augmentation on epochs 30, 60, and 90 of the baseline model and continue training until epoch 163 to discover the optimal time to introduce augmentation. Epochs 30, 60, and 90 represent three distinct stages in the training process: initial loss rate stabilising, loss rate stagnate before learning rate decrease, and loss rate stagnate after learning rate decrease.
Experiments
The range of learning rates that provide a stable convergence reduces as batch size increases
In the most extreme case, we reduce the training set to 4% of the original dataset, meaning a batch size of 128 would likely degrade performance
Large batches tend to converge to sharp minimizers leading to poor generalization due to the numerous large eigenvalues in the Hessian on convergence
Small batches, on the other hand, tend to converge to flat minimizers, which have smaller Hessian eigenvalues
They generate more noise in gradient calculations, decreasing the chance of the gradient dropping into a sharp local minima
Based on these observations, we train the small and medium datasets using three learning rate strategies: 1) the original strategy from [He et al., 2015], 2) using a batch size of 128 with no learning rate schedule, and 3) using a batch size of 8 with original learning rate schedule.
Results & Discussion
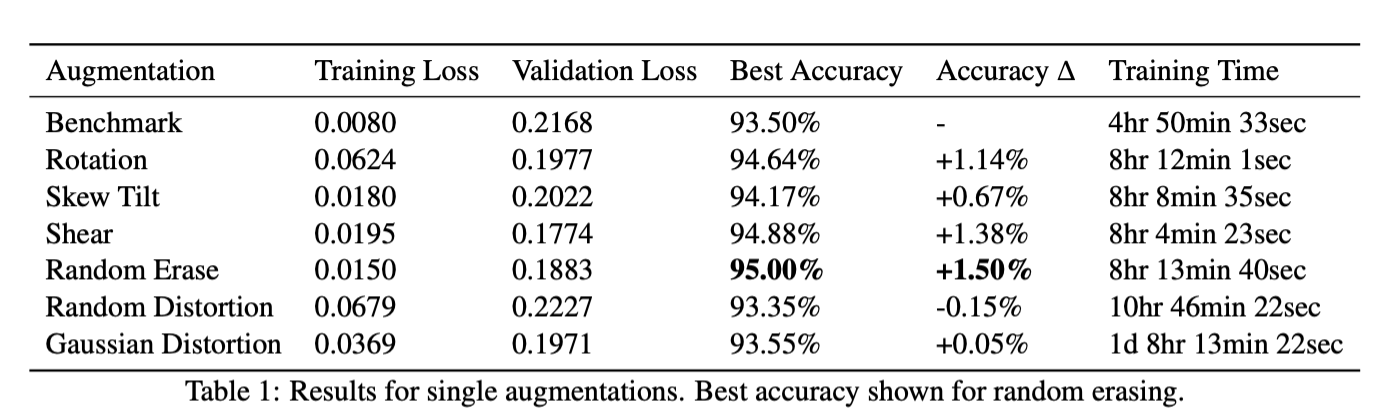
Single Augmentations
Random erasing shows the best improvement in accuracy of +1.5%
Both distortion augmentations obtain worse or similar results to the baseline
The complexity of the augmentation effects the overall training time. Traditional, more simplistic augmentations require little processing time, leading to increases in training time of ∼ 3.5 hours. [Gaussian distortion](Gaussian distortion.md) sees the most significant increase in training time of 665%
We apply each augmentation separately, leading to the dataset increasing from 50k training images to 250k. This leads to the most accurate result seen throughout all experiments of 95.85%
Our method of applying several single augmentations produces better generalization properties
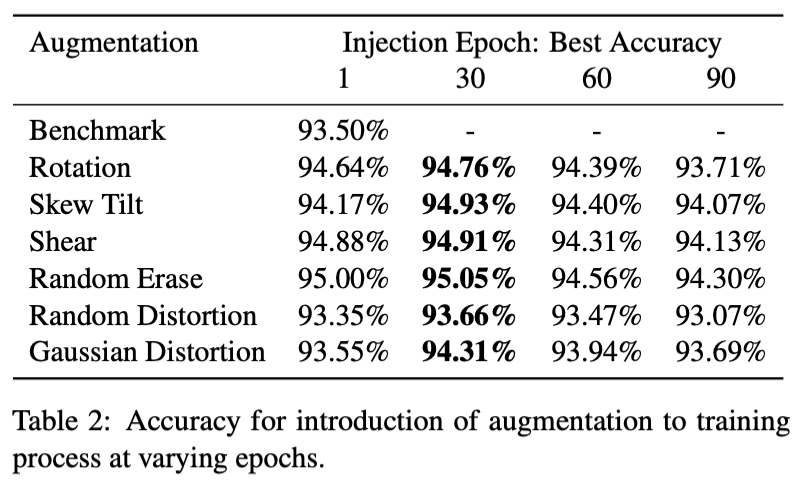
Varying Augmentation Injection Epoch
epoch 30 is the optimal time to introduce augmentation
y injecting augmentation on the 30th epoch, the model combats the effects of overfitting better with increases in accuracy from +0.05% up to +0.76%
Epoch 30 is the point in the training process when the reduction in loss rate begins to decrease drastically, i.e. the model falls into a local minima point
The slight improvements in accuracy over the baseline result for introduction at epoch 90 support this conclusion
The model has already overfit the training data and can no longer benefit from the augmentation’s generalization properties.
Epoch 60 presents a more interesting point in the training process. The form of augmentation appears to dictate whether the model will have better generalization properties than training with augmentation from scratch but will always be worse than injection at epoch 30
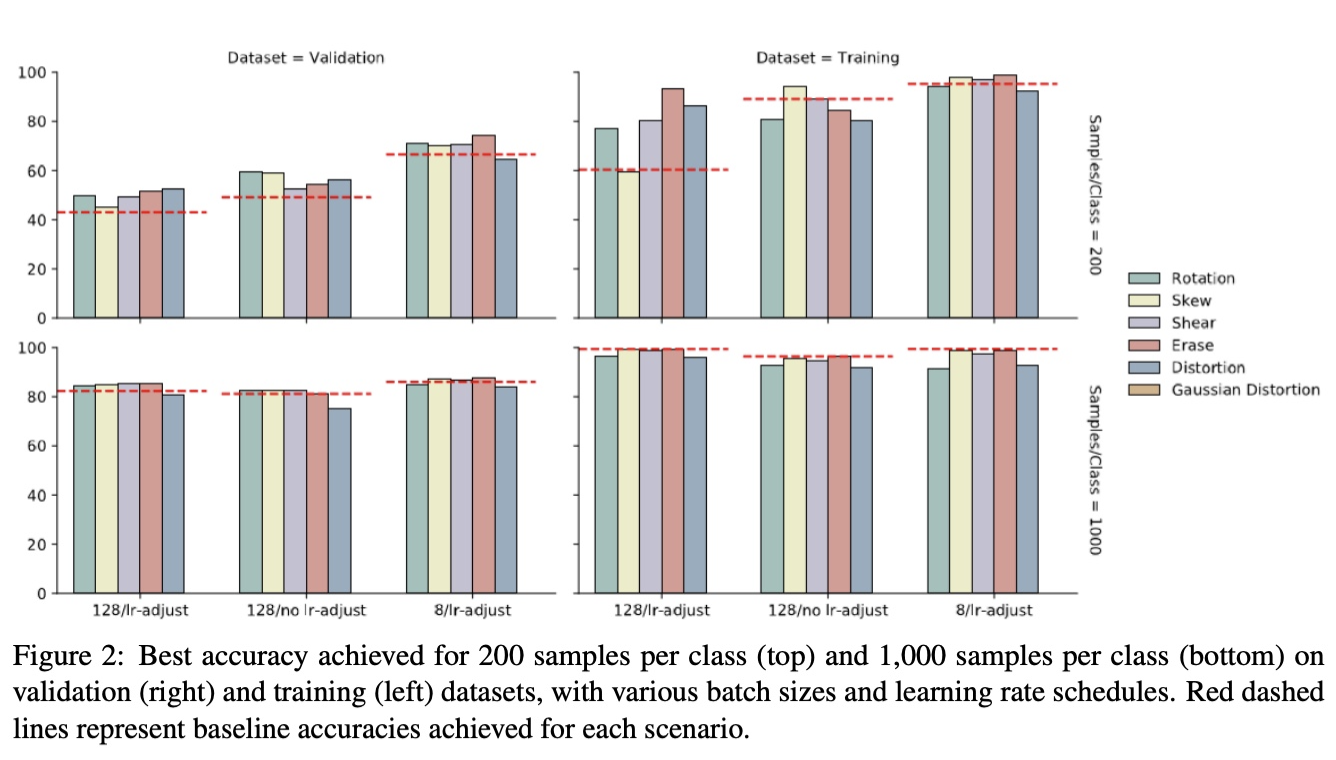
Varying Sample Size
For the small dataset, by decreasing the batch size from 128 to 8, the validation accuracy is shown to improve by +31.45% using random erasing (74.46%) when compared to the baseline (43.01%)
augmentation is most effective in training when data is scarce
overfitting, as measured by high accuracy on the training set, in many of the augmentation results is more severe than for the baseline
his would contradict current assumptions that augmentation improves generalization by preventing overfitting in the case of all NNs
In many of these cases where augmentation has proven to prevent overfitting the sample size for each class is large
generalization of the model is better in the presence of augmentation
With smaller datasets using augmentation increases the models ability to learn certain features present in the training set as augmentation can only alter the data already available, i.e. the model will see similar images twice as much so is more likely to overfit.
For the medium dataset, the best accuracy is achieved by random erasing trained with a batch size of 8 at 87.45%, which is an improvement of +6.3% over the baseline.
The importance of the learning rate adjustment schedule is apparent with the accuracy decreasing for each model when not applied
Augmentation does reduce overfitting with the most significant decrease occurring for the small batch size
At this scale, augmentation has similar effects on accuracy as seen in the full dataset
When the model has large volumes of training data available, augmentation only slightly increases the generalization capabilities of the network as a large amount of variance already exists
Conclusion
The initial augmentation gives rise to the most significant increase in training time with any additional augmentations adding little overhead
processing time required to apply said augmentation to the dataset, which must be considered when choosing a form of augmentation to apply
combining multiple single augmentations with the original dataset is the most effective augmentation strategy with an increase in accuracy of +2.36% to 95.85%
Random distortion and [Gaussian distortion](Gaussian distortion.md) are the worst forms of augmentation tested leading to changes in accuracy of -0.15% and +0.05%, respectively
This is due to the augmented images not representing the original class and highlights the importance of the choice of augmentation
The most effective form of single augmentation is found to be random erasing with an increase in accuracy of +1.5%. This is due to its ability to combat the effects of occlusion, and is similar to preventing co-adaption through the use of Dropout.
An interesting avenue to explore is the generalization and overfitting properties of augmentation for data scarcity
Validation accuracy is seen to improve with augmentation, with the most significant improvement of +31.45% for random erasing, indicating better generalization capabilities.
However, the model also appears to overfit the training data more
Exploring the interaction of augmentation with more advanced optimizers such as the Adam optimizer, could lead to further improvements in accuracy and training times
generalization gap between SGD and Adam can be reduced by switching from Adam to SGD during the training process
During the switching process the learning rate for SGD is calculated as noted in [Keskar and Socher, 2017] and must be switched at the optimal time to ensure better generalization properties.
Building on this approach, the optimizer switching approach could be combined with data augmentation potentially yielding improvements in accuracy.
Injecting augmentation at epoch 30 yielded the best improvements in accuracy for single augmentations, indicating a learning curriculum is most effective for augmentation
Late injection of augmentation improves the generalization capabilities of the network similar to the optimizer switching method of [Keskar and Socher, 2017].