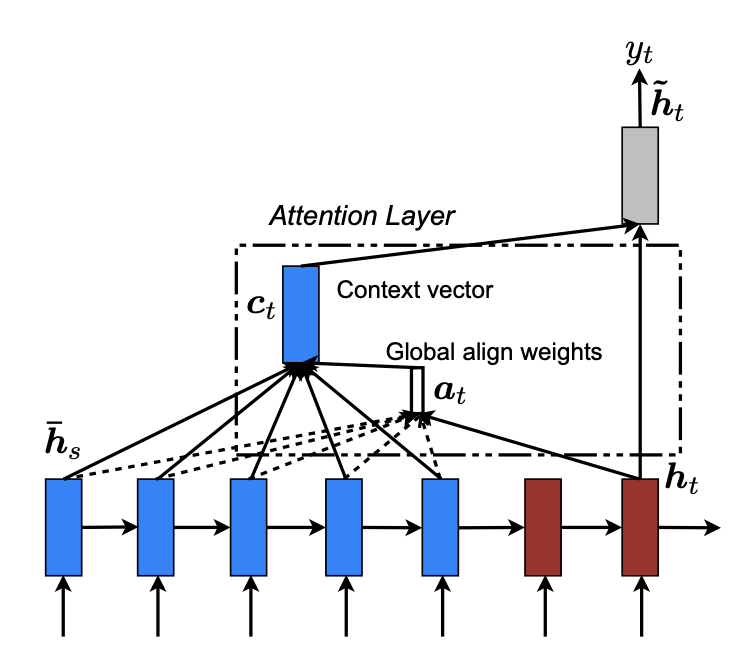
Multiplicative Attention fatt(hi,sj)=hiTWasj Since Additive Attention performs better for scale, use a factor Scaled Dot Product Attention